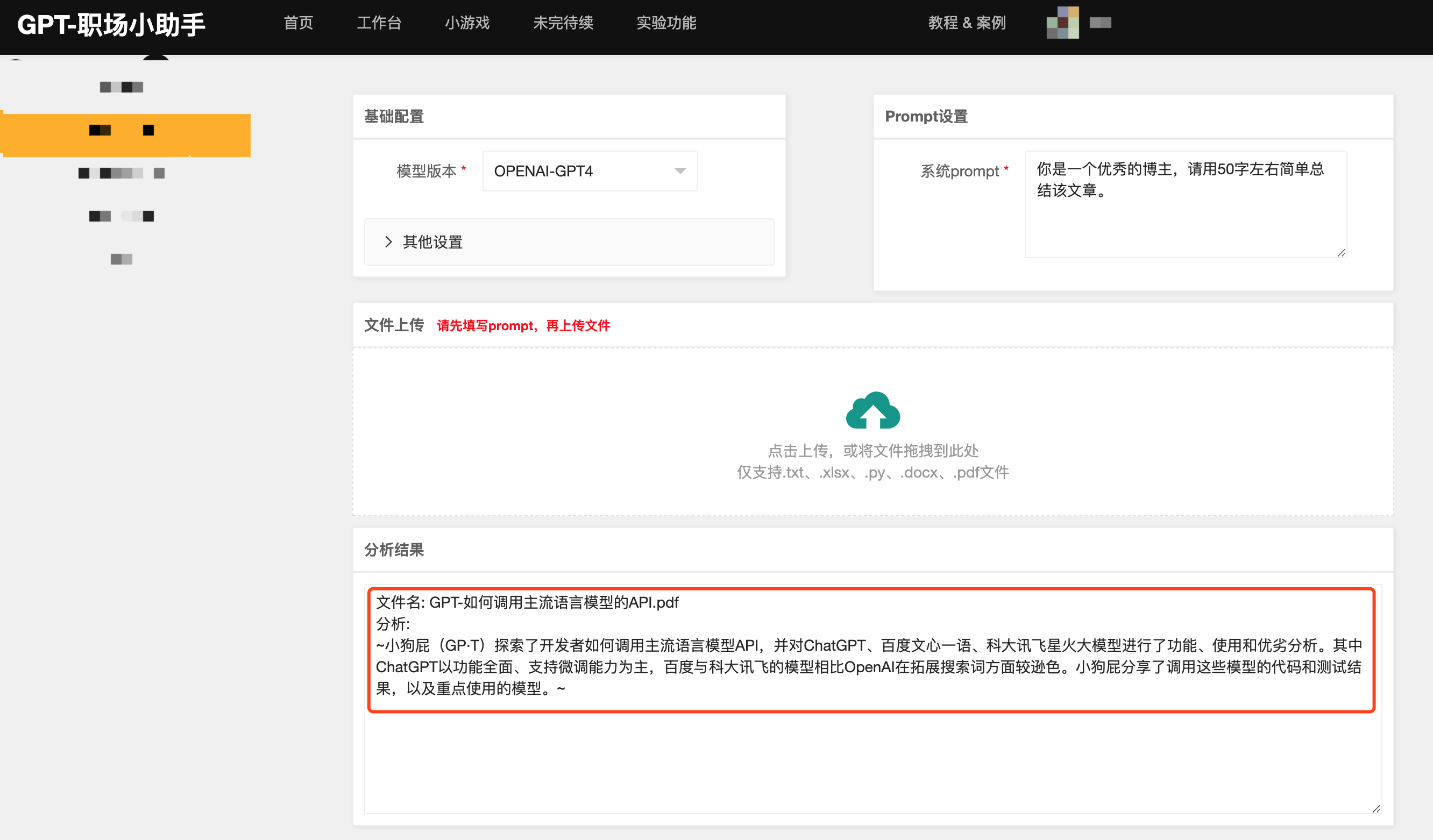
大模型,小探索 —— 调用主流语言模型的API
微信公众号内容地址: https://mp.weixin.qq.com/s/12tyDd6Os583rBF4IeyfCg
ChatGPT一声炮响,世界迎来了大模型时代。
这里是小狗屁(GP·T)的大模型探索专题,在这里我将记录和介绍在大模型探索中的点点滴滴,开启 GPT 的成长之路。
今天,让我们先来探索作为个人开发者,如何调用主流语言模型的 API。
GPT 火了,可这英文啥意思?
GPT(Generative Pre-trained Transformer),基于转换器的生成式预训练模型,成为了生成式人工智能的重要框架。
中文听起来着实拗口,但其实从英文组成上可以看出,主要三个核心:生成式模型、预训练、Transformer 架构,这在 GPT 的论文中均有体现,感兴趣的读者可以自行研究,或者跟着小狗屁在以后的专题内容中慢慢了解。
都有哪些产品?
继 OpenAI 发布 ChatGPT 后,国内外各企业和机构都快速跟进,推出了相应的产品,比较主流的有:
- 百度的文心一言
- 阿里的通义千问
- 腾讯的混元 AI 大模型
- 字节的豆包
- 百川智能的百川大模型
- 科大讯飞的星火大模型
- Google 的 Gemini
- …
经过了较为苛刻的筛选(对个人开发者开放 + 部分免费)之后,小狗屁目前重点使用的是 ChatGPT、文心一言和星火大模型。
OpenAI - ChatGPT
成为开发者
先看文档,https://platform.openai.com/docs/overview
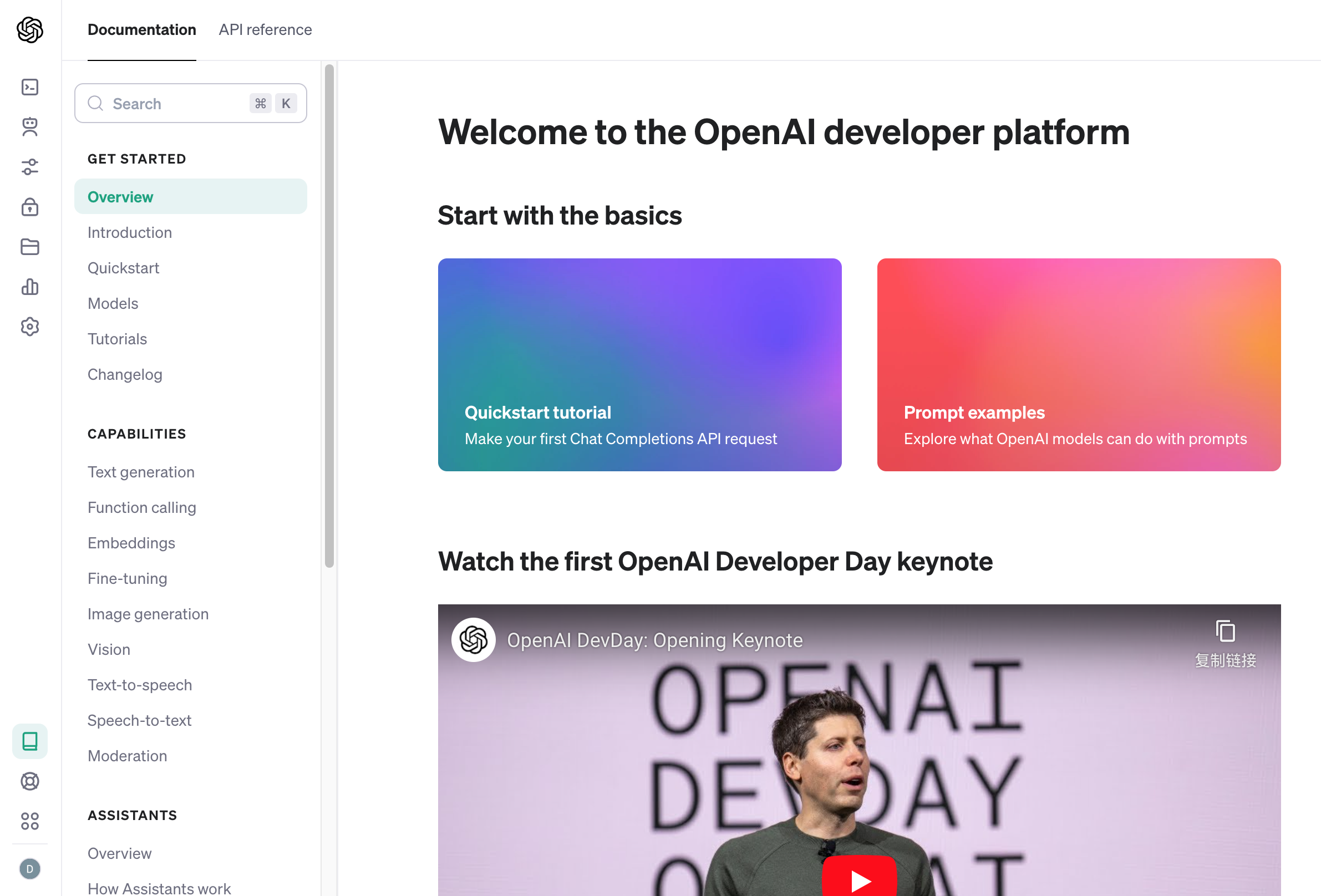
首先是功能和 API 文档,主要支持文本理解和生成、图片理解、图片生成、微调等功能。
申请成为个人开发者,也只要在同页面注册账号即可;登录后,侧边栏可以展开,具备 API-KEY 注册,费用统计,以及账户费用预充值(平台注册账号后,会默认送一部分费用,但有使用限制,比如无法调用 GPT-4)等功能。
至于收费标准,则位于OpenAI 官网首页,核心如下:
| 模型 | 输入 | 输出 |
|---|---|---|
| gpt-4 | $0.03 / 千tokens | $0.06 / 千 tokens |
| gpt-3.5-turbo-1106 | $0.0010 / 千tokens | $0.0020 / 千 tokens |
文本处理代码
大体流程为:
- API-KEY
- 系统提示词 + 用户提示词 + 处理内容,以及创新性、是否流式等参数设置。
- 获取结果;若是流式调用,则基于 Python 的生成器,实现逐步输出内容的效果。
- 协议:基于 HTTP 协议,客户端单向请求服务端;若是流式调用,为SSE(Server-sent Events)模式。
openai.py
# https://pypi.org/project/openai/1.2.4/
from openai import OpenAI
def get_response(api_key,
input_text, model_config, temperature_config,
system_prompt='', user_prompt='', ex_user_prompt='', ex_assistant_prompt='',
stream=False):
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=api_key,
)
# 系统提示词
messages = [{"role": "system", "content": system_prompt}]
if ex_user_prompt != "" and ex_assistant_prompt != "":
# 示例,一问一答
messages.append({"role": "user", "content": ex_user_prompt})
messages.append({"role": "assistant", "content": ex_assistant_prompt})
if user_prompt != "":
# 用户提示词 + 内容处理
messages.append({"role": "user", "content": f"{user_prompt}:{input_text}"})
else:
# 内容处理
messages.append({"role": "user", "content": input_text})
response = client.chat.completions.create(
model=model_config,
messages=messages,
temperature=temperature_config, # 创新性
stream=stream, # 是否流式输出
)
return response
def get_result(response):
return response.choices[0].message.content
def get_stream_result(response):
for chunk in response:
content = chunk.choices[0].delta.content
if not content:
content = '~'
yield content
测试代码及结果
def test_text_get_result(stream=False):
api_key = ''
input_text = '光明优倍减脂肪50%鲜牛奶 950ml'
temperature_config = 1
model_config = 'gpt-3.5-turbo-1106'
system_prompt = '结果输出不超过10个词,且不出现"搜索词"和"关键词"字样,并将所有词都用";"连接成一行'
user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词'
ex_user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词:东鹏0糖能量饮料(6罐装) 335ml*6'
ex_assistant_prompt = '会议;商用;健身;运动;补充能量;东鹏;能量;饮料;罐装'
response = openai.get_response(api_key,
input_text, model_config, temperature_config,
system_prompt, user_prompt, ex_user_prompt, ex_assistant_prompt,
stream)
if stream:
for result in openai.get_stream_result(response):
print(result)
else:
print(openai.get_result(response))
if __name__ == "__main__":
# 非流式
print('文本处理,非流式调用结果:')
test_text_get_result()
# 流式
print('文本处理,流式调用结果:')
test_text_get_result(True)
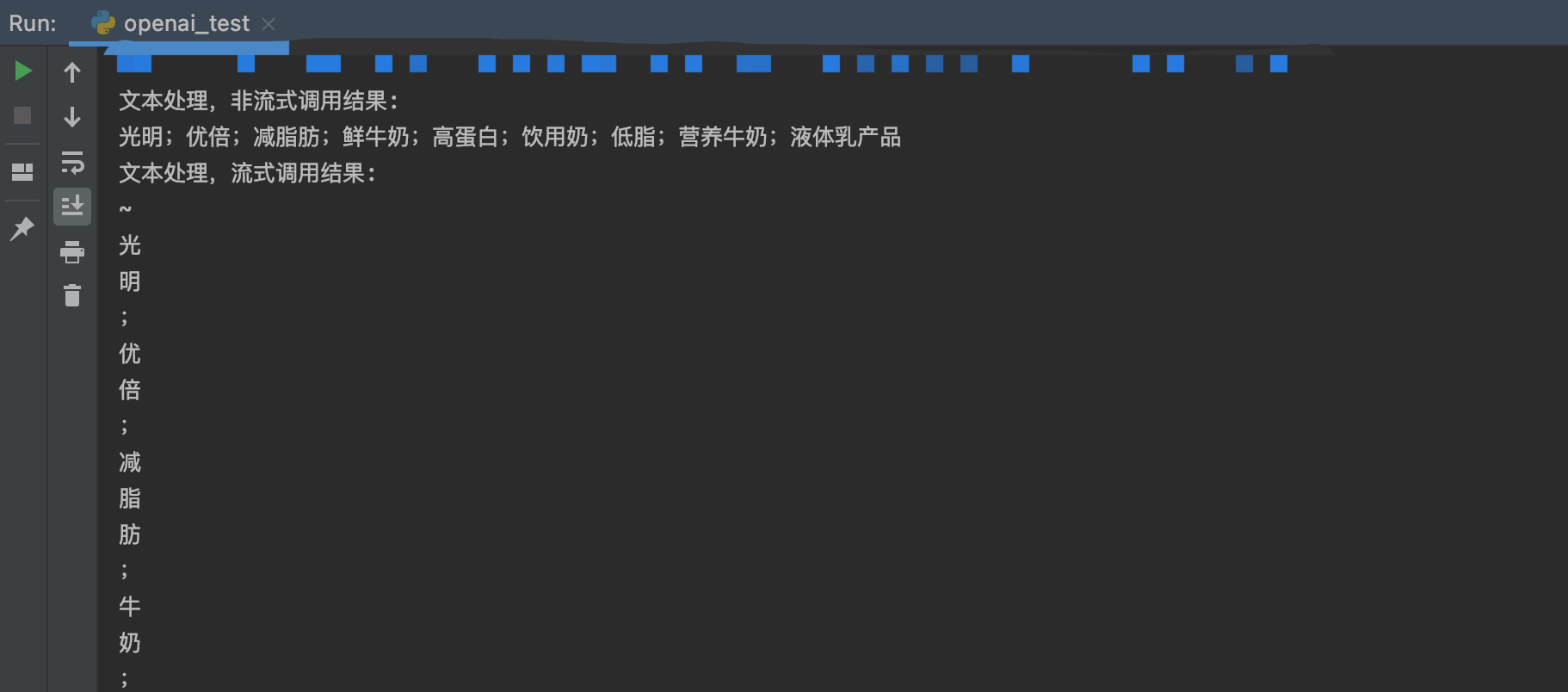
输出结果符合目标要求,包含关键词和拓展搜索词,且输出格式也与系统提示语的要求一致;内容上,除了提取了关键词,拓展搜索词确实有“拓展”的效果,可以提升搜索转化效率。
优劣分析
| 优势 | 劣势 |
|---|---|
| 功能齐全,对个人开放了微调能力 | 需要 VPN,且文档为英文 |
| GPT-4,GPT-4,GPT-4 | 调用 GPT-4 不免费,且账户以美元为单位 |
百度 - 文心一言
成为开发者
先看文档,https://yiyan.baidu.com/developer/doc
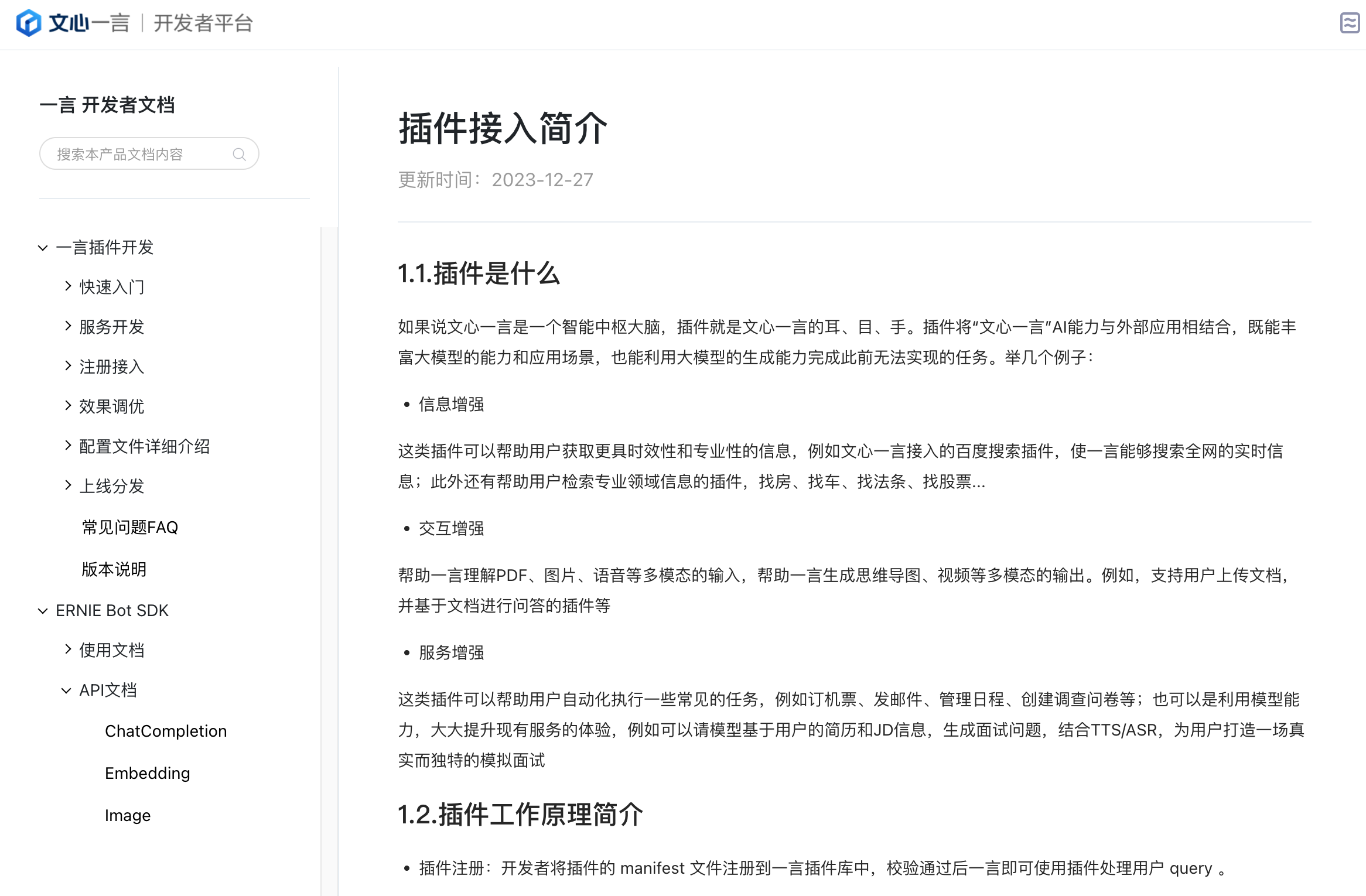
首先是插件和 API 文档,能力更多的在插件上(类似于 OpenAI 的 GPT Store)。而 API 支持较少,对个人开发者仅支持文本理解和生成、图片生成,暂不支持微调。
而想申请成为 API 的个人开发者,则需要进入百度的AI Studio 飞桨平台,获取 ACCESS-TOKEN。收费上,每个账户初始有100 万 token 的免费额度,但没有使用详情页面,以及未看到之后的收费方式。
另一种目前暂未体验的,则是在百度智能云千帆大模型平台成为开发者,得到一体化的大模型 API 处理服务(包括微调、数据集、Prompt 工程等),核心收费如下:
| 模型 | 输入 | 输出 |
|---|---|---|
| ERNIE-Bot 4.0 | 0.12 元 / 千 tokens | 0.12 元 / 千 tokens |
| ERNIE-Bot-8k | 0.024 元 / 千 tokens | 0.048 元 / 千 tokens |
| ERNIE-Bot | 0.012 元 / 千 tokens | 0.012 元 / 千 tokens |
文本处理代码
大体流程为:
- ACCESS-TOKEN
- 用户提示词 + 处理内容,以及是否流式等参数设置;由于百度没有系统提示词,但出于和 OpenAI 的对齐,增加一轮对话来实现系统提示词效果。
- 获取结果;若是流式调用,则循环拉取结果,基于 Python 的生成器,实现逐步输出内容的效果。
- 协议:基于 HTTP 协议,客户端单向请求服务端;若是流式调用,为SSE(Server-sent Events)模式
wenxin.py
# https://yiyan.baidu.com/developer/doc#Glm002aat
import erniebot
def get_response(api_key,
input_text, model_config,
system_prompt='', user_prompt='', ex_user_prompt='', ex_assistant_prompt='',
stream=False):
messages=[
# 增加一轮对话,实现系统提示语效果
{"role": "user", "content": f"{system_prompt}"},
{"role": "assistant", "content": "好的"}
]
if ex_user_prompt != "" and ex_assistant_prompt != "":
messages.append({"role": "user", "content": ex_user_prompt})
messages.append({"role": "assistant", "content": ex_assistant_prompt})
if user_prompt != "":
messages.append({"role": "user", "content": f"{user_prompt}:{input_text}"})
else:
messages.append({"role": "user", "content": repr(input_text)})
response = erniebot.ChatCompletion.create(
_config_=dict(
api_type="aistudio",
access_token=api_key,
),
model=model_config,
messages=messages,
stream=stream,
)
return response
def get_result(response):
return response['result']
def get_stream_result(response):
for chunk in response:
content = chunk.result if 'result' in chunk else ""
yield content
测试代码及结果
def test_text_get_result(stream=False):
api_key = ''
input_text = '光明优倍减脂肪50%鲜牛奶 950ml'
model_config = 'ernie-bot'
system_prompt = '结果输出不超过10个词,且不出现"搜索词"和"关键词"字样,并将所有词都用";"连接成一行'
user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词'
ex_user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词:东鹏0糖能量饮料(6罐装) 335ml*6'
ex_assistant_prompt = '会议;商用;健身;运动;补充能量;东鹏;能量;饮料;罐装'
response = wenxin.get_response(api_key,
input_text, model_config,
system_prompt, user_prompt, ex_user_prompt, ex_assistant_prompt,
stream)
if stream:
for result in wenxin.get_stream_result(response):
print(result)
else:
print(wenxin.get_result(response))
if __name__ == "__main__":
# 非流式
print('文本处理,非流式调用结果:')
test_text_get_result()
# 流式
print('-----------------------------')
print('文本处理,流式调用结果:')
test_text_get_result(True)
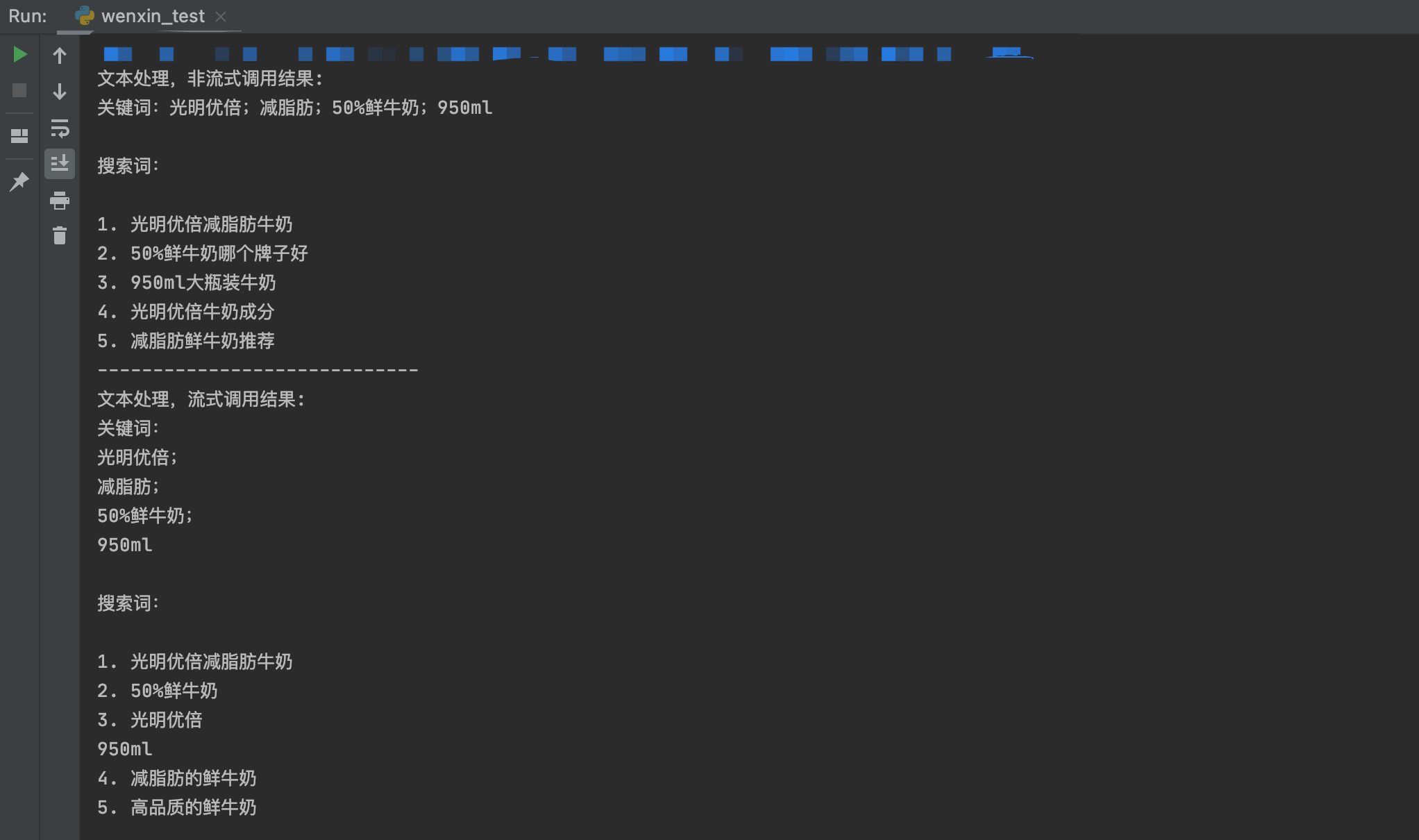
与 OpenAI 相比,提取关键词能力相似,但是拓展搜索词要较为逊色,几乎没有拓展和泛化;同时,系统提示词的内容没有得到反馈,即没有拼接结果。
优劣分析
| 优势 | 劣势 |
|---|---|
| 结合上千帆平台,功能齐全,对个人开放了微调等能力 | 文心一言插件、飞桨、千帆多个平台,账户管理较为混乱 |
| 国内直接访问,成本低 | 效果比起同 level 的 OpenAI 模型,较为逊色 |
| API 使用形式与 OpenAI 相一致,学习成本低 |
科大讯飞 - 星火大模型
成为开发者
先看文档,https://www.xfyun.cn/doc/spark/Web.html
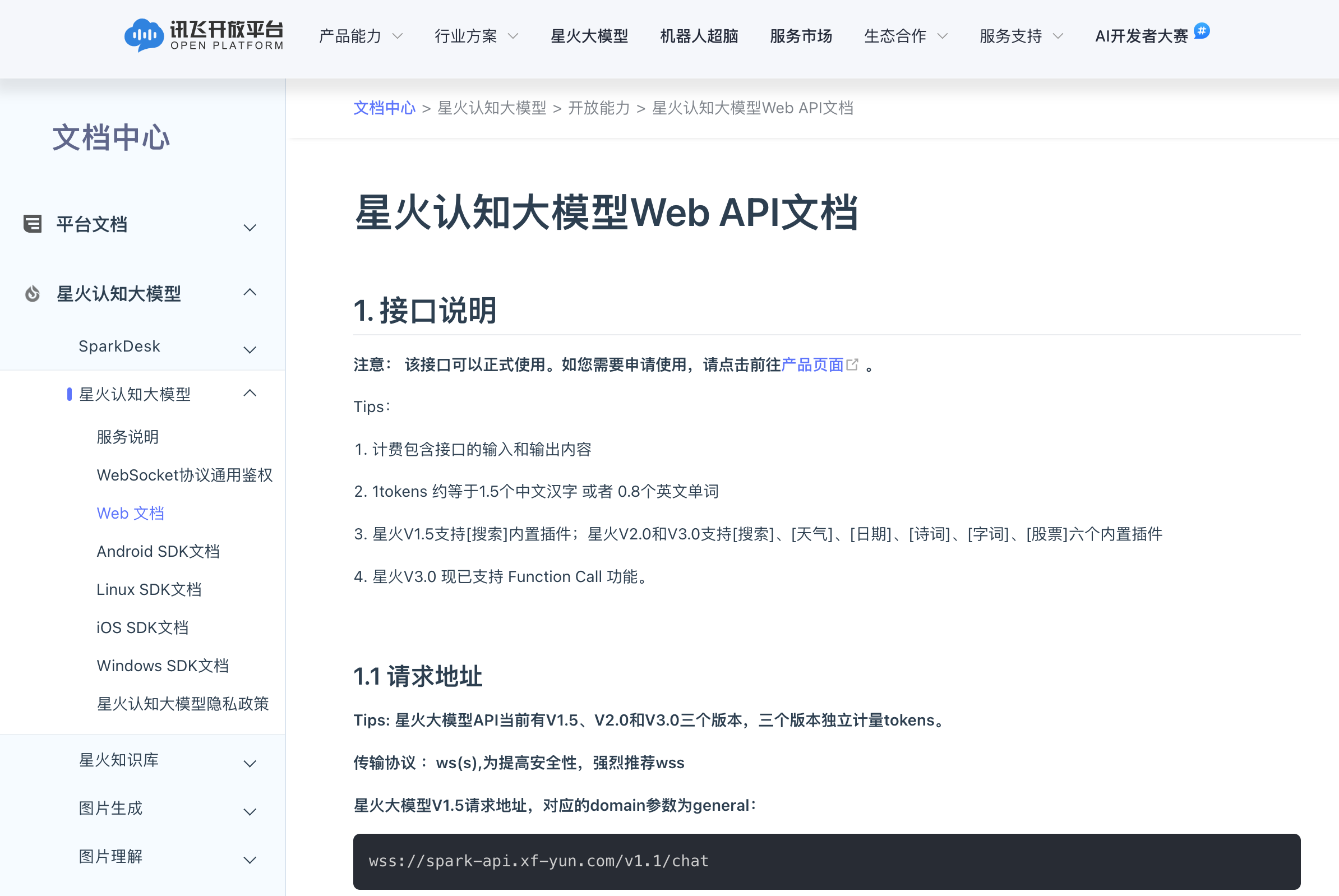
首先是功能和 API 文档,主要支持文本理解和生成、图片理解、图片生成、微调等功能。
申请成为个人开发者,则需要在星火大模型首页注册;登录后,创建应用,得到 APP-ID,API-KEY, API-SECRET 进行使用,支持 WebAPI、Android、iOS、Windows 和 Linux 平台,新用户有200 万 token 的免费额度。
至于收费标准,也在首页,与其他平台计费方式不同,科大讯飞只提供了 token 套餐: | 模型 | 费用 | | — | — | | V3.0 | 一年 0.5 亿 tokens,1500 元;一年 1 亿 tokens,2800 元;… | | V1.5 | 一年 0.5 亿 tokens,750 元;一年 1 亿 tokens,1400 元;… |
文本处理代码
大体流程为:
- 不支持 Web SDK,因此需要大量网络请求和处理的代码
- APP-ID,API-KEY, API-SECRET 完成鉴权
- 用户提示词 + 处理内容;由于科大讯飞没有系统提示词,但出于和 OpenAI 的对齐,增加一轮对话来实现系统提示词效果。
- 获取结果:收集流式回复,整合成完整结果
- 协议:基于 WebSocket 协议,客户端和服务端双向通信,服务端流式提供结果
kdxf_content_process.py
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
answer = ""
# 生成url
def create_url(api_key, api_secret, spark_url):
host = urlparse(spark_url).netloc
path = urlparse(spark_url).path
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + host + "\n" \
+ "date: " + date + "\n"\
+ "GET " + path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(api_secret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{api_key}", algorithm="hmac-sha256", headers="host date request-line", ' \
f'signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": host
}
# 拼接鉴权参数,生成url
url = spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws, one, two):
print(" ")
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, domain=ws.domain, question=ws.question))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
data = json.loads(message)
code = data['header']['code']
global answer
if code != 0:
print(f'请求错误: {code}, {data}')
answer = data
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
answer += content
if status == 2:
ws.close()
def gen_params(appid, domain, question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"temperature": 0.5,
"max_tokens": 2048
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
def getlength(text):
length = 0
for content in text:
temp = content["content"]
leng = len(temp)
length += leng
return length
def checklen(text):
while getlength(text) > 8000:
del text[0]
return text
kdxf.py
# https://www.xfyun.cn/doc/spark/Web.html
import base64
import ssl
import websocket
import kdxf_content_process
def get_response(api_key, input_text,
system_prompt='', user_prompt='', ex_user_prompt='', ex_assistant_prompt=''):
appid = api_key['app_id']
api_secret = api_key['secret']
api_key = api_key['key']
# 准备参数
kdxf_content_process.answer = ""
domain = "generalv3"
spark_url = "wss://spark-api.xf-yun.com/v3.1/chat"
messages=[
{"role": "user", "content": f"{system_prompt}"},
{"role": "assistant", "content": "好的"}
]
if ex_user_prompt != "" and ex_assistant_prompt != "":
messages.append({"role": "user", "content": ex_user_prompt})
messages.append({"role": "assistant", "content": ex_assistant_prompt})
if user_prompt != "":
messages.append({"role": "user", "content": f"{user_prompt}:{input_text}"})
else:
messages.append({"role": "user", "content": input_text})
question = kdxf_content_process.checklen(messages)
# websocket建立
websocket.enableTrace(False)
ws_url = kdxf_content_process.create_url(api_key, api_secret, spark_url)
ws = websocket.WebSocketApp(ws_url,
on_message=kdxf_content_process.on_message,
on_error=kdxf_content_process.on_error,
on_close=kdxf_content_process.on_close,
on_open=kdxf_content_process.on_open)
ws.appid = appid
ws.question = question
ws.domain = domain
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
# 等待处理完成,并返回结果
return kdxf_content_process.answer
def get_result(response):
if 'header' in response:
return response['header']['message']
return response
测试代码及结果
def test_text_get_result():
api_key = {
'app_id': '',
'secret': '',
'key': ''
}
input_text = '光明优倍减脂肪50%鲜牛奶 950ml'
system_prompt = '结果输出不超过10个词,且不出现"搜索词"和"关键词"字样,并将所有词都用";"连接成一行'
user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词'
ex_user_prompt = '请帮我提取商品中4个关键词,并扩展5个极有可能能够搜索到该商品的搜索词:东鹏0糖能量饮料(6罐装) 335ml*6'
ex_assistant_prompt = '会议;商用;健身;运动;补充能量;东鹏;能量;饮料;罐装'
response = kdxf.get_response(api_key, input_text,
system_prompt, user_prompt, ex_user_prompt, ex_assistant_prompt)
print(kdxf.get_result(response))
if __name__ == "__main__":
# 非流式
print('文本处理,非流式调用结果:')
test_text_get_result()
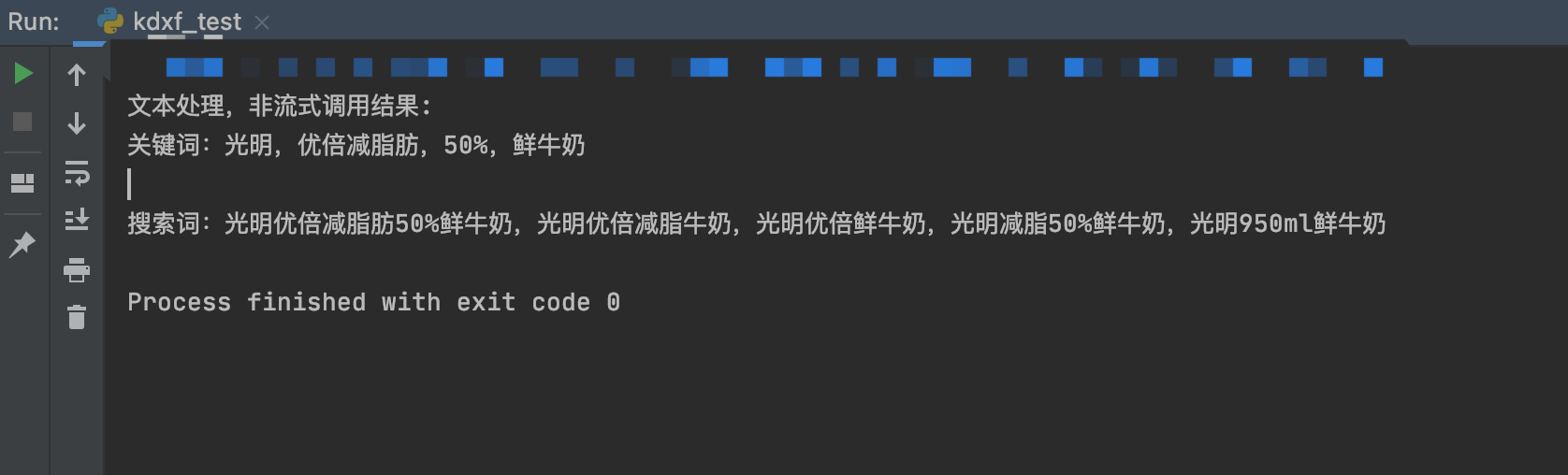
整体与百度相似,即与 OpenAI 相比,提取关键词能力相似,但是拓展搜索词要较为逊色,几乎没有拓展和泛化;同时,系统提示词的内容也没有得到反馈,即没有拼接结果。
优劣分析
| 优势 | 劣势 |
|---|---|
| 功能齐全,对个人开放了微调等能力 | API 使用形式特殊(三个部分的 API-KEY、无 WEB-SDK、Web Socket 通信协议),有学习成本 |
| 国内直接访问,成本低 | 效果比起同 level 的 OpenAI 模型,较为逊色 |
总 结 - GPT