国考出分了,数据分析一波
微信公众号内容地址: https://mp.weixin.qq.com/s/WtAjZhUNqF05vEFOqYOgAw
不知不觉,”水硕”已经毕业了几个月,躺平进入了 2024。回看 2023,百废待兴——”水硕日记”还有一堆课程未能总结,秋招目前 0 offer 😂,最大的努力,可能就是裸考参加了接近 300w 人报名的国考!
既然 1 月初出了分,本着大过年的,考都考了的心态,小刀觉得不如来做一波数据分析,也为”水硕”挽个尊。
数据概览
在国家公务员局官网的 2024 年度考试录用公务员专题中的相关下载中,可以拿到面试人员名单的 Excel,里面会提供最低入面分数。
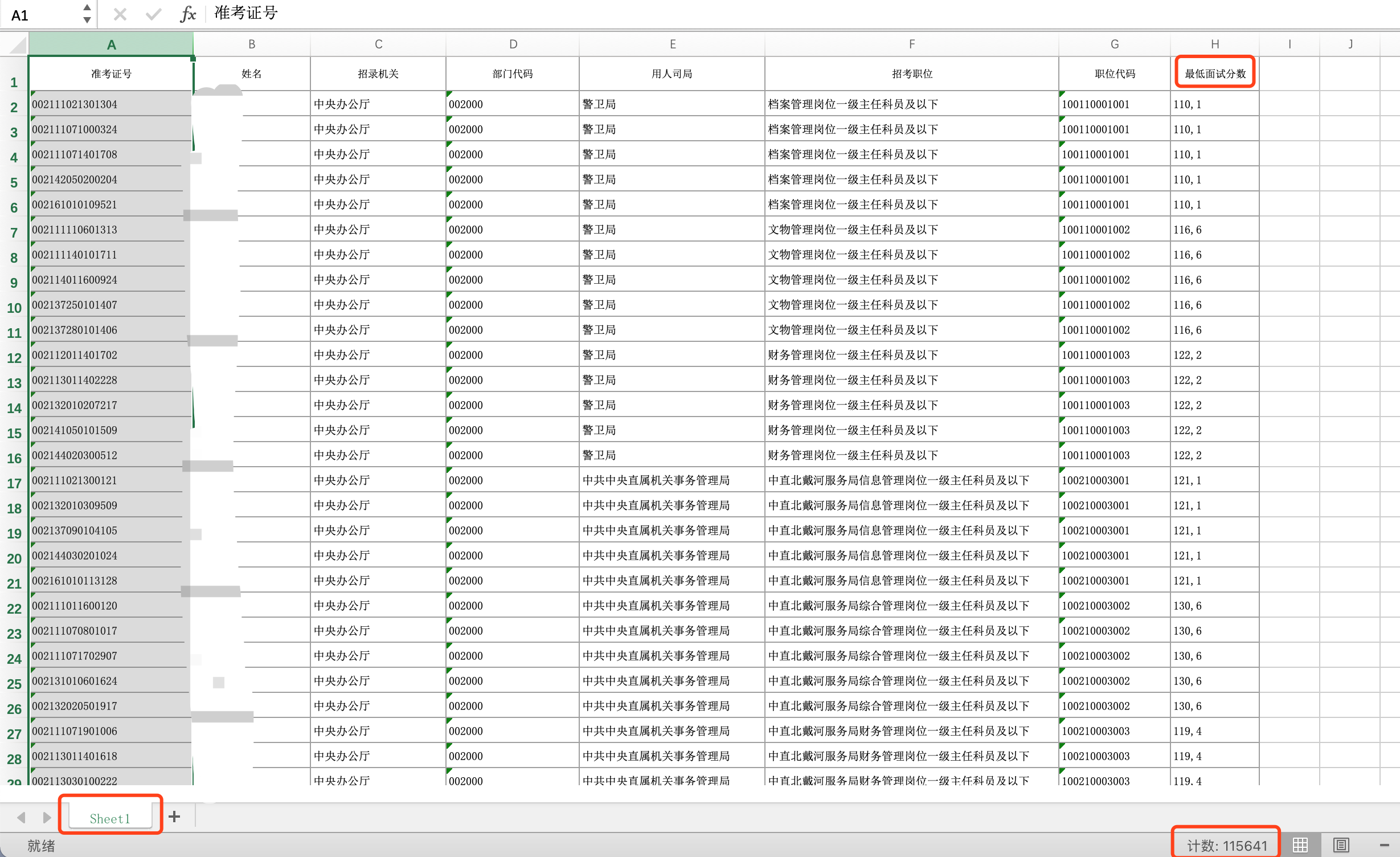
简单查看 Excel,对数据进行初步了解:
- 只有一个工作表,该表内总数据量在 11w 量级。
- 招录机关、用人司局、招考职位 和 最低面试分数 将会是主要的分析字段,而姓名字段则需要考虑数据隐私。
- 准考证号是唯一字段,职位代码按照业务理解应该是唯一字段,等价于招录机关+用人司局+招考职位的组合。
业务认知
数据分析结果的解释能力,跟对业务的理解程度相关。因此,小刀先尽量总结在本次体验过程中,对国考笔试规则的理解:
-
报考期间,根据报名的职位信息 Excel(简称报名表)中的职位地区、属性、专业、学历等要求,进行合理的选择。
-
考试科目和分数,分两类
- 一类是需要考专业课的岗位,例如金管局等,考的是行测、申论和专业课,分别按照 25%、25%和 50%的比例计算总分,满分 100(而公安机关,比例则是 40%,30%,30%)。
- 另一类则不需要考专业课,只考行测和申论,满分 200。
- 首先要达标国家合格线
- 2024 年的合格线为,行测达到 60 分,行测和申论总共达到 105 分,专业课达到 45 分。(市级和县级、西部地区,分数标准相应降低)
-
不同的岗位,根据竞争情况不同,进面分数线不相同,这也是数据分析的价值所在——探索分布、问题和原因。
-
同样由于竞争情况不同,存在调剂策略。
分析环境准备
总的来说,有诸多方法和工具进行分析,例如
- 以 Excel 为核心,如本地或者在线 Excel、以及各种插件;
- 以在线表格平台为核心,如飞书多维表格、Tableau 等 BI 平台;
- 以编程为核心,如 Python、Jupyter Notebook(IPython)、以及 Deepnote 等平台;
- 以 AI 为核心,如 GPT、以及在上述的工具中使用 AI 插件。
考虑到 11w 的数据量,在 Excel 中处理已经出现卡顿以及它也超过了大部分在线平台的免费服务范围,小刀最终选择在 Github 上建立了 Jupyter Notebook 项目,以便于代码版本管理,同时使用 Codespaces 实现在线编程和观察结果。出于数据隐私考虑,在上传 Excel 到线上前,移除了姓名字段。
数据分析
总体分析
除了已知的总数据量在11w,即笔试出线人数,这里小刀还希望了解下总岗位数、进面分数等情况。相关的代码,则可以依靠 ChatGPT 帮忙实现。
df['招录机关-用人司局-招考职位'] = df.apply(lambda row: f"{row['招录机关']}_{row['用人司局']}_{row['招考职位']}", axis=1)
print("职位代码去重后总数: " + str(df['职位代码'].nunique()))
职位代码去重后总数: 6493
print("招录机关-用人司局-招考职位组合去重后总数: " + str(df['招录机关-用人司局-招考职位'].nunique()))
招录机关-用人司局-招考职位组合去重后总数: 16006
df['最低面试分数'].describe()
count 115640.000000
mean 112.478784
std 23.569302
min 45.250000
25% 111.800000
50% 120.600000
75% 126.600000
max 144.700000
从报名信息表以及网络信息知道,2024 年国考提供的岗位总数为 18948 个,招聘总人数为 39561 人;
而国考出分的数据里,职位代码数量为 6493 个,而通过招录机关-用人司局-招考职位组合之后得到的数字却是 16006 个,相比而言,后者更合理。
一方面,这说明"职位代码"字段与岗位并不是一一对应,甚至是一对多,虽然难以置信,但是回头查看报名的 Excel,确实会发现存在多个不同的岗位却拥有相同的职位代码(并不理解,且大为震惊)。
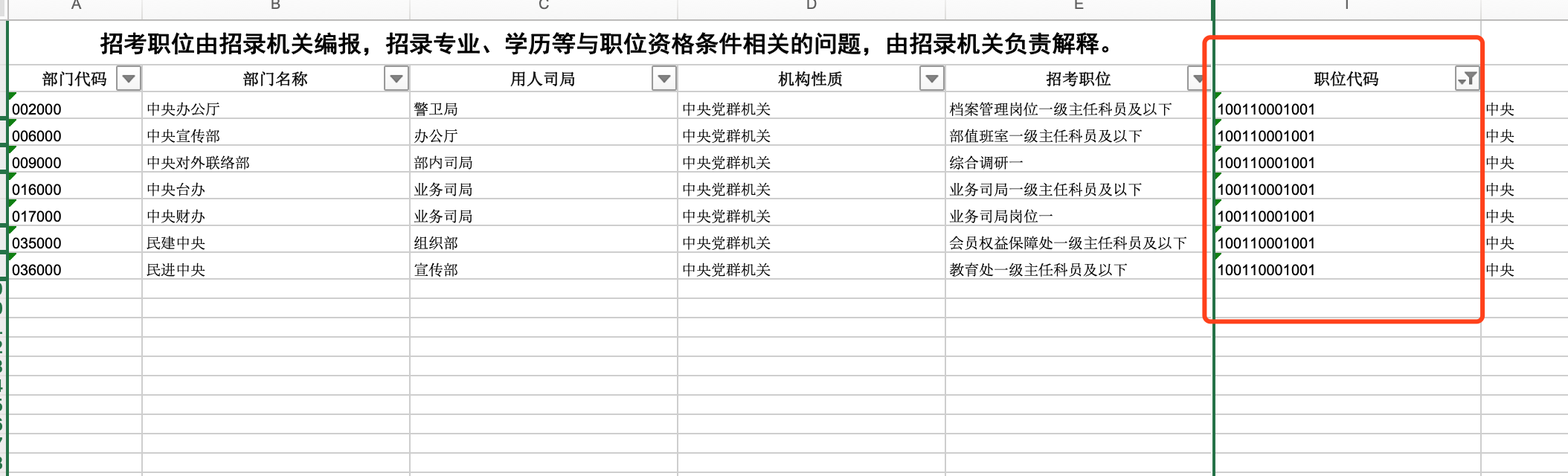
另一方面,出分后的岗位总数相比于报名时的岗位数少了接近 3000 个,也即这么多岗位可能没人报名,或者是考生均没有高于国家合格线,无人出线。
除此之外,用总人数除以岗位数,可知平均来看,每个岗位约有 7 个人进行面试环节的竞争。
观察最低进面分数的分布,可知最小为 45 分,最大为 144 分,方差很大。这是因为两类岗位的总分不一致引起的,因此首先需要分成两类,分别分析。
分类处理
分类的策略以 89 分作为标准,因为不涉及专业课的岗位中,国家合格线的最低标准为 90 分,而包含了专业课的岗位,几乎不会出现高于 90 分。
df_below_89 = df[df['最低面试分数'] < 89]
df_above_89 = df[df['最低面试分数'] >= 89]
print("包含专业课的岗位总数: " + str(df_below_89['招录机关-用人司局-招考职位'].nunique()))
包含专业课的岗位总数: 1760
print("不含专业课的岗位总数: " + str(df_above_89['招录机关-用人司局-招考职位'].nunique()))
不含专业课的岗位总数: 14246
df_below_89['最低面试分数'].describe()
count 16598.000000
mean 58.278703
std 4.996526
min 45.250000
25% 54.831250
50% 58.472500
75% 61.510000
max 72.925000
df_above_89['最低面试分数'].describe()
count 99042.00000
mean 121.56193
std 8.34317
min 90.00000
25% 116.60000
50% 122.40000
75% 127.50000
max 144.70000
先看包含专业课的岗位,总岗位数为 1760 个,而进面人数为 16598 人,平均每个岗位面试阶段 9 个人进行竞争;同时,最低进面分数最小值为 45 分,最大值为 72 分,分位数上来看,上下 1/4 的分数跃迁较大,大多数人分数集中在 54 到 61 分。值得一提的是,小刀也在有些网站(如公务员考试网)上看到统计的数据为需要组织专业考试的岗位数仅为 348 个,经过确认,发现该数据应该指的是需要在面试阶段组织专业能力测试,与该笔试阶段的数据不矛盾。另一方面,最大值为 72 分,与划分标准的 89 分相差较远,这也可以反向证明,该划分策略合理,应该没有将高分划分到不涉及专业课的类别中。
再看不含专业课的岗位,总岗位数为 14246 个,而进面人数为 99042 人,平均每个岗位面试阶段不到 7 个人进行竞争;同时,最低进面分数最小值为 90 分,最大值为 144 分,大多数人分数集中在 116 到 127 分。
对比来看,涉及专业课的岗位和不涉及专业课考试的岗位进面人数比约为 3:20,岗位数比约为 3:25,仅从数据上来看,含专业课的岗位面试阶段的竞争要较为激烈些,但该结论没有考虑到各个岗位招录人数本身也存在不同,要想得出论证合理的结论,还得结合报名表中的招录数据进一步分析。
总的来说,该阶段得到的有用的结论可能是:
- 报名了不含专业课考试的岗位,按照平均水平想要进入面试,总分需要达到 122 分左右。
-
报名了含有专业课考试的岗位,按照平均水平想要进入面试,总分需要达到 58 分左右。
- 按照行测、申论、专业课的 25%、25%、50%的比例来算:
- 如果行测和申论总分在 105 分,则专业课需要达到 63.5 分;
- 如果专业课在 45 分,则行测和申论总分需要达到 142 分(从数据来看,已经邻近最大值,难度较大);
- 如果行测和申论总分在 122 分,则专业课需要达到 55 分。
包含专业课的岗位分析
这里主要关心高分的岗位、低分的岗位,以及岗位分数随地区的分布。
高分和低分岗位
# 取分数最高的10个岗位
# 先排序,再分组,第一个head取每个组里的topN,第二个head取整个组的topN
df_below_89[['招录机关-用人司局-招考职位','最低面试分数']]\
.sort_values(by='最低面试分数', ascending=False)\
.groupby('招录机关-用人司局-招考职位')\
.head(1)\
.head(10)
国家金融监督管理总局_经济金融岗二_一级主任科员及以下 72.925
国家金融监督管理总局天津监管局_国家金融监督管理总局天津监管局_监管部门一级主任科员及以下 72.825
国家金融监督管理总局山东监管局_国家金融监督管理总局莱芜监管分局_监管部门一级主任科员及以下 72.525
商务部_离退休干部局_一级主任科员及以下(法语) 72.300
国家金融监督管理总局江苏监管局_国家金融监督管理总局江苏监管局_监管部门一级主任科员及以下 72.300
国家金融监督管理总局陕西监管局_国家金融监督管理总局陕西监管局_监管部门一级主任科员及以下 72.175
国家金融监督管理总局黑龙江监管局_国家金融监督管理总局黑龙江监管局_监管部门一级主任科员及以下 71.750
国家金融监督管理总局江苏监管局_国家金融监督管理总局苏州监管分局_监管部门一级主任科员及以下 71.725
国家金融监督管理总局江苏监管局_国家金融监督管理总局常州监管分局_监管部门一级主任科员及以下 71.650
国家金融监督管理总局江西监管局_国家金融监督管理总局江西监管局南昌县级派出机构_监管部门一级... 71.625
# 取分数最低的10个岗位
# 先排序,再分组,第一个head取每个组里的topN,第二个head取整个组的topN
df_below_89[['招录机关-用人司局-招考职位','最低面试分数']]\
.sort_values(by='最低面试分数', ascending=True)\
.groupby('招录机关-用人司局-招考职位')\
.head(1)\
.head(10)
国家金融监督管理总局云南监管局_国家金融监督管理总局大理监管分局_财会部门一级主任科员及以下 45.250
南宁铁路公安局_南宁铁路公安局_柳州铁路公安处基层所队民警 45.340
新疆出入境边防检查总站_新疆出入境边防检查总站_红其拉甫出入境边防检查站一级警长及以下(二) 45.460
国家金融监督管理总局安徽监管局_国家金融监督管理总局安庆监管分局岳西县级派出机构_综合部门一... 45.750
国家金融监督管理总局广西监管局_国家金融监督管理总局贺州监管分局_财会部门一级主任科员及以下 45.850
国家金融监督管理总局河北监管局_国家金融监督管理总局河北监管局辖内县级派出机构_综合部门一级... 46.075
国家移民管理局东兴遣返中心_国家移民管理局东兴遣返中心_东兴遣返中心执行队一级警长及以下(一) 46.250
国家金融监督管理总局新疆监管局_金融监管总局阿克苏监管分局_监管部门一级主任科员及以下 46.375
国家金融监督管理总局新疆监管局_金融监管总局巴音郭楞监管分局_统计信息部门一级主任科员及以下 46.525
国家金融监督管理总局新疆监管局_金融监管总局塔城监管分局和布克赛尔县级派出机构_监管部门一级... 46.575
低分岗位相对容易分析,也符合预期,主要集中在西部地区,竞争较小(当然这里存在进一步优化分析空间,国家合格线在不同地区也不相同,因此省级、市级、西部地区的理论最低分数线本身也不一致,一起比较,则自然西部地区会占多数);高分岗位则有些意外,并非是只有一线城市竞争激烈,分布并没有呈现明显趋势。
平均岗位分数随地区的分布
# 平均岗位分数与地区的分布(不考虑中央级别)
# 地区数组
regions = ['北京', '天津', '上海', '重庆',
'内蒙古', '广西', '西藏', '宁夏', '新疆',
'河北', '山西', '辽宁', '吉林', '黑龙江', '江苏',
'江西', '山东', '河南', '湖北', '湖南', '广东',
'海南', '四川', '贵州', '云南', '西藏', '陕西',
'甘肃', '青海', '浙江', '安徽', '福建']
# 遍历每个地区,计算平均录取分数
region_scores = {}
for region in regions:
region_data = df_below_89[df_below_89['招录机关-用人司局-招考职位'].str.contains(region)] # 筛选出特定地区的数据
average_score = region_data['最低面试分数'].mean() # 计算平均录取分数
# print(f"地区 {region} 的平均录取分数为 {average_score}")
region_scores[region] = average_score
sorted(region_scores.items(), key=lambda x: x[1], reverse=True)[:10]
[('江苏', 63.08758536585365),
('浙江', 62.569803278688525),
('江西', 61.534659090909095),
('天津', 60.209364754098374),
('湖南', 59.938614649681526),
('四川', 59.699225663716824),
('北京', 59.67088486140726),
('广东', 59.521358543417364),
('重庆', 59.288492063492065),
('山西', 59.269492385786805)]
# 读取中国地图数据
# china_map = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
china_map = gpd.read_file('https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json').to_crs('EPSG:4573')
# 获取地图数据中的地区名
map_region_names = china_map['name'].tolist()
# 模糊匹配地区名并添加分数到 GeoDataFrame
scored_regions = []
for input_region, score in region_scores.items():
matched_region, _ = process.extractOne(input_region, map_region_names)
scored_regions.append({'Region': matched_region, 'Score': score})
df_scores = gpd.GeoDataFrame(scored_regions, columns=['Region', 'Score'])
merged = china_map.merge(df_scores, how='left', left_on='name', right_on='Region')
# 绘制地图
fig, ax = plt.subplots(1, 1, figsize=(15, 10))
merged.boundary.plot(ax=ax, linewidth=0.8)
merged.plot(column='Score', ax=ax, legend=True, legend_kwds={'label': "Score"}, cmap='Blues', linewidth=0.8)
# 在地图上标注分数值
for x, y, label in zip(merged.geometry.centroid.x, merged.geometry.centroid.y, merged['Score']):
ax.text(x, y, f"{round(label, 1)}", fontsize=8, ha='center', va='center')
plt.show()
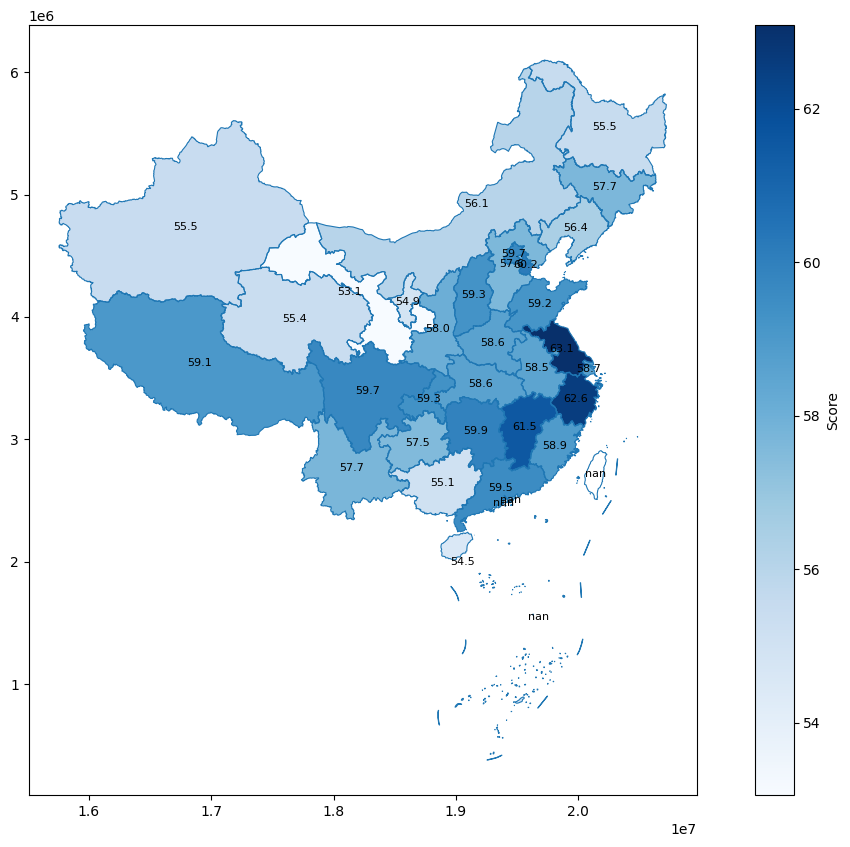
从分布看出,江苏、浙江、江西、天津的平均分数较高,已经突破 60 分;而甘肃、宁夏等地,则相对不高。需要注意的是,这里是按照目标岗位的所在地的分布,不能等价于考生所在地区,考生可能是往家乡考、也可能是想往其他地区去发展。
不含专业课的岗位分析
高分和低分岗位
# 代码省略,高分岗位
国家税务总局青岛市税务局_国家税务总局青岛市市北区税务局_一级行政执法员(七) 144.7
国家税务总局江苏省税务局_国家税务总局南京市江宁区税务局_一级行政执法员(二) 143.5
国家税务总局江苏省税务局_国家税务总局南京市建邺区税务局_一级行政执法员(四) 143.3
河南省气象局_河南省许昌市气象局_办公室一级主任科员及以下 143.3
国家税务总局山东省税务局_国家税务总局烟台高新技术产业开发区税务局_一级行政执法员(三) 143.2
国家税务总局浙江省税务局_国家税务总局舟山市税务局第二税务分局_一级行政执法员(二) 143.2
国家税务总局浙江省税务局_国家税务总局绍兴市越城区税务局_一级行政执法员(一) 142.1
国家税务总局宁波市税务局_国家税务总局慈溪市税务局_一级行政执法员(三) 142.0
国家税务总局江苏省税务局_国家税务总局江阴市税务局_一级行政执法员(四) 142.0
国家税务总局河南省税务局_国家税务总局郑州航空港实验区税务局第一税务分局_一级行政执法员(四) 141.9
# 代码省略,低分岗位
国家统计局四川调查总队_国家统计局四川调查总队_洪雅调查队一级科员 90.0
国家税务总局黑龙江省税务局_国家税务总局宝清县税务局_一级行政执法员(二) 90.2
呼和浩特海关_乌海海关_植物检疫监管一级行政执法员 90.3
长江海事局_宜宾海事局_宜宾海事局一级行政执法员(一) 90.3
中国人民银行安徽省分行_中国人民银行池州市分行_综合业务部门一级主任科员及以下 90.4
国家税务总局黑龙江省税务局_国家税务总局拜泉县税务局_一级行政执法员(二) 90.4
国家矿山安全监察局甘肃局_国家矿山安全监察局甘肃局_监察执法一处三级主任科员及以下 90.4
哈尔滨海关_同江海关_办公综合一级行政执法员 90.4
国家税务总局河北省税务局_国家税务总局阜城县税务局_一级行政执法员 90.4
甘肃省气象局_甘肃省白银市气象局_业务科一级主任科员及以下 90.5
可以看出,不含专业课的岗位中,高分几乎全部出现在税务局,竞争还是挺激烈的。
平均岗位分数随地区的分布
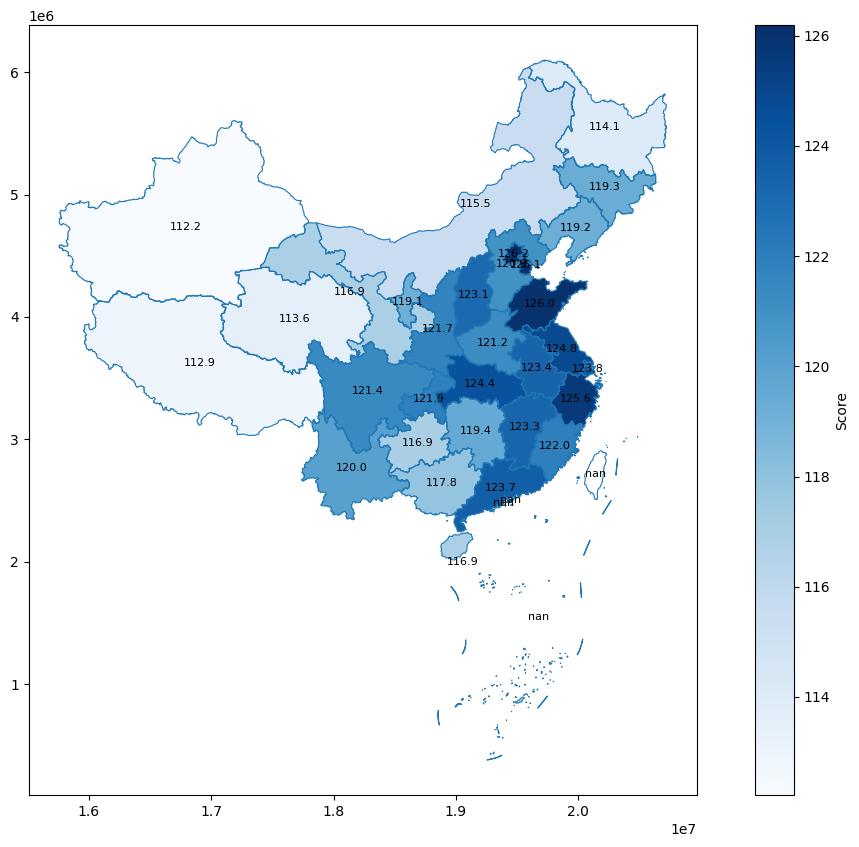
与之前类似,江苏、浙江等地平均分数依然保持较高值,而没有了专业课的限制后,北京和山东也相继进入高分排行榜。
更多探索
除了之前已经发现的因为缺少招考人数字段导致有些分析不够严谨,同样的,因为缺乏职位属性和专业等字段,这里无法进行进一步的探索,如文理科的分数分布。同样的,这些可以通过与报名表的匹配扩充字段,来进行更深入的分析。
总 结
本内容对应的代码地址位于 https://github.com/coderzzy/data_analysis/blob/main/notebooks/guokao2024.ipynb;
以下是 ChatGPT 帮忙做的总结(看来有待提升 😂):
该文档为个人总结的国家公务员考试(国考)数据分析报告。记录了作者参加万人规模国考的体验,使用 Jupyter Notebook 等工具进行数据处理和分析。分析涉及考试录用公务员名单、最低面试分数等数据,并考虑地域和专业课的影响。结果显示,含专业课的岗位面试阶段竞争较激烈,不含专业课的岗位中税务局竞争尤为激烈。文档最后提出了分析限制和进一步拓展的方向。