大模型,小探索 —— 免费算力? 在“超算互联网”部署大模型
微信公众号内容地址: https://mp.weixin.qq.com/s/jrB8z1gSt6CF16ifeLyK3w
算力,就是新一代的“石油”
聊完了大模型的 API 调用,接下来可以摸索摸索大模型部署的门道了。
不过万事开头难,没有 💰 更难。作为 AI 能源的算力,虽然单价相对不贵,但大模型对算力的消耗也挺可观。好在,小狗屁在机缘巧合之中,发现了个似乎免费的算力渠道——超算互联网平台。
超算互联网
https://www.scnet.cn/ui/mall/index.html#/mall/home
该平台的背景,是继东数西算工程之后,科技部发起成立国家超算互联网联合体。
“我们希望的超算互联网是由各大超算中心提供算力,以各种软件的方式将其提供给用户,就像京东和淘宝出售货物那样,使得更多用户能方便获得需要的资源,让超算的使用更为普及。”中国科学院院士、超算互联网总体专家组组长钱德沛表示,“到那时候,用户对超算算力的使用,就如同用水、用电一样便利,做到任何地方、任何人、任何时间都可以获得算力来支持应用”。
小狗屁的个人理解,这就类似于国家电网、中石油等企业,统筹分配基础能源,从而提升规模效应,降低边际成本,促进相关行业发展。
“体验官”计划
https://www.scnet.cn/home/news/15750.html
个人可以通过报名申请成为“体验官”,注册账号体验网站,并通过填写问卷或提交报告等方式,获得算力资源包等奖励。即使不成为“体验官”,现阶段也可以在体验专区试用免费算力,香!
功能探索
整个网站机制跟淘宝网基本一致,无额外学习成本。作为用户,可以查看各种商品,也可以申请成为商户,提供各种商品。
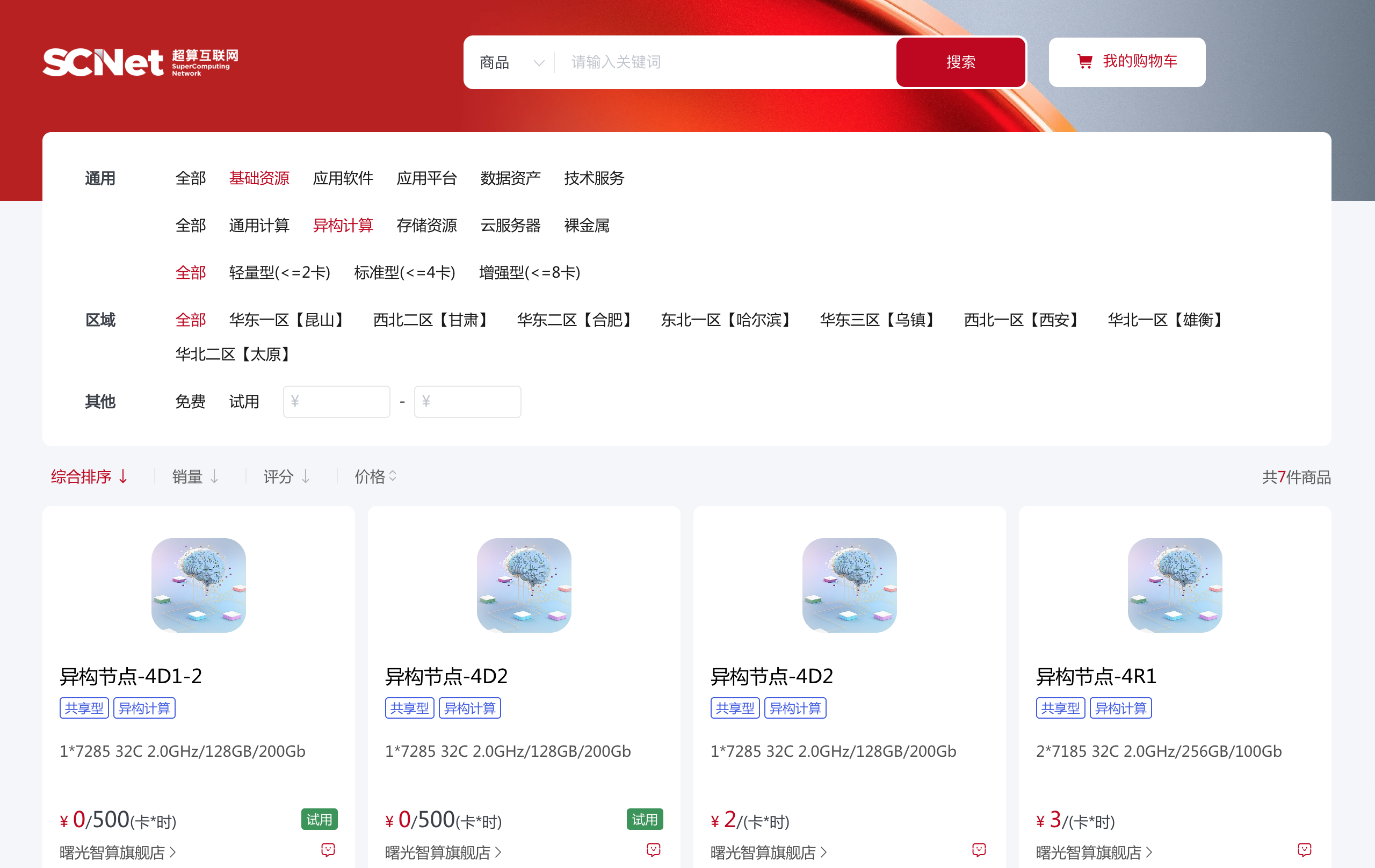
商品主要分为五个大类:
- 基础资源:云服务器、云算力(CPU、GPU)等。
- 应用软件:云软件,需要购买配套的基础资源,才能方便使用。
- 应用平台:从超算互联网平台,关联到外部平台,使用其服务。
- 数据资产:卖产品,源码、数据集等产品,可直接下载。
- 技术服务:卖服务,下单之后商家提供技术咨询等服务。
下单之后,可以从控制台-我的商品中进行查看。
基础资源
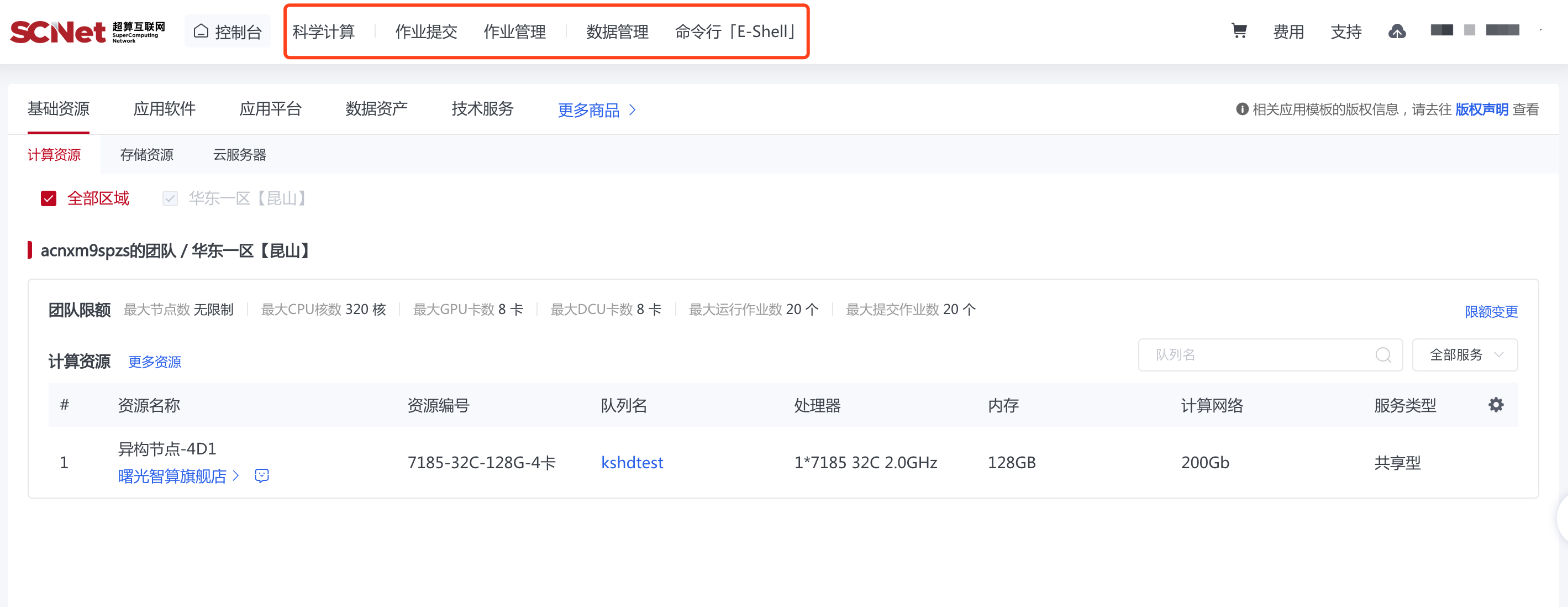
基础资源在商品页面,主要是查看功能。真正的使用需要结合最上方的作业管理等功能,后半篇章大模型部署中会体现的更加明显。(总的来说,作业管理用来执行任务,数据管理则类似于是管理个人“网盘”中的文件)
应用软件
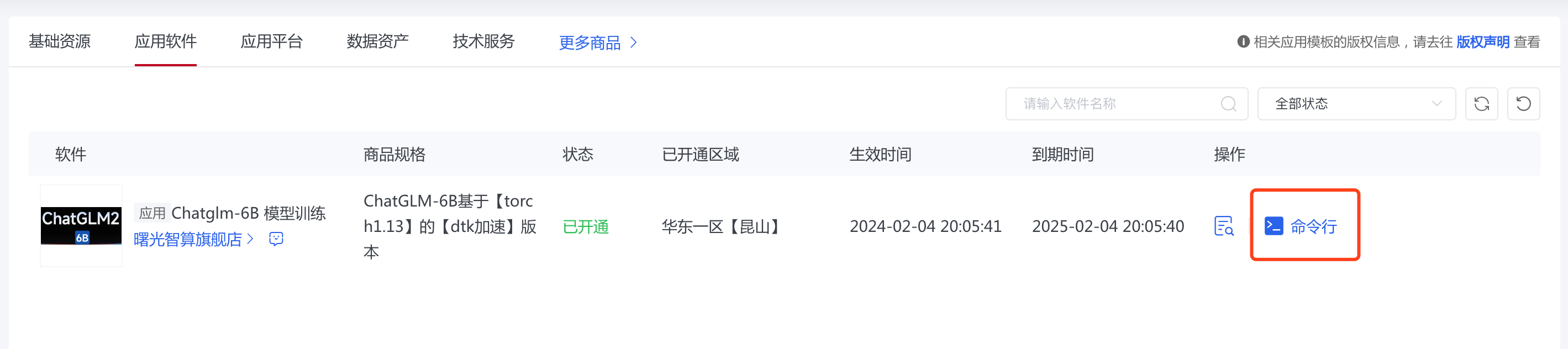
应用软件与基础资源一般相互配合使用,以图中清华大学的 ChatGLM 大模型为例,提供了跳转命令行的快捷按钮;若是带有界面的软件,这里提供的可能会是跳转至软件界面的快捷按钮。
应用平台
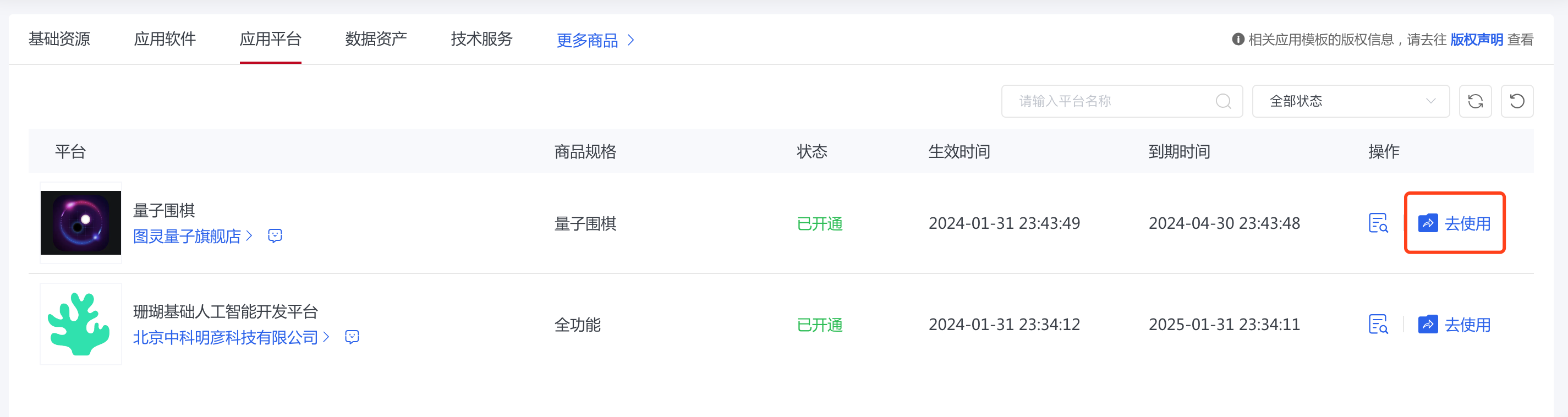
应用平台提供的则是“去使用”按钮,点击后会跳转至外部网站,继续使用该网站的功能。
数据资产
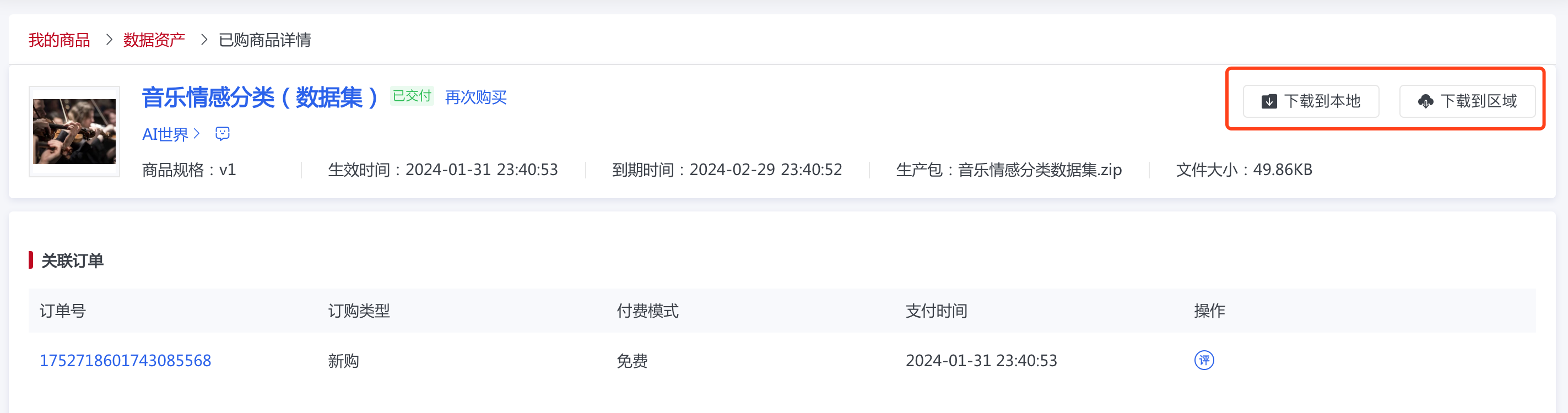
数据资产提供了下载到本地或者下载到区域(个人“网盘”)的按钮。
技术服务
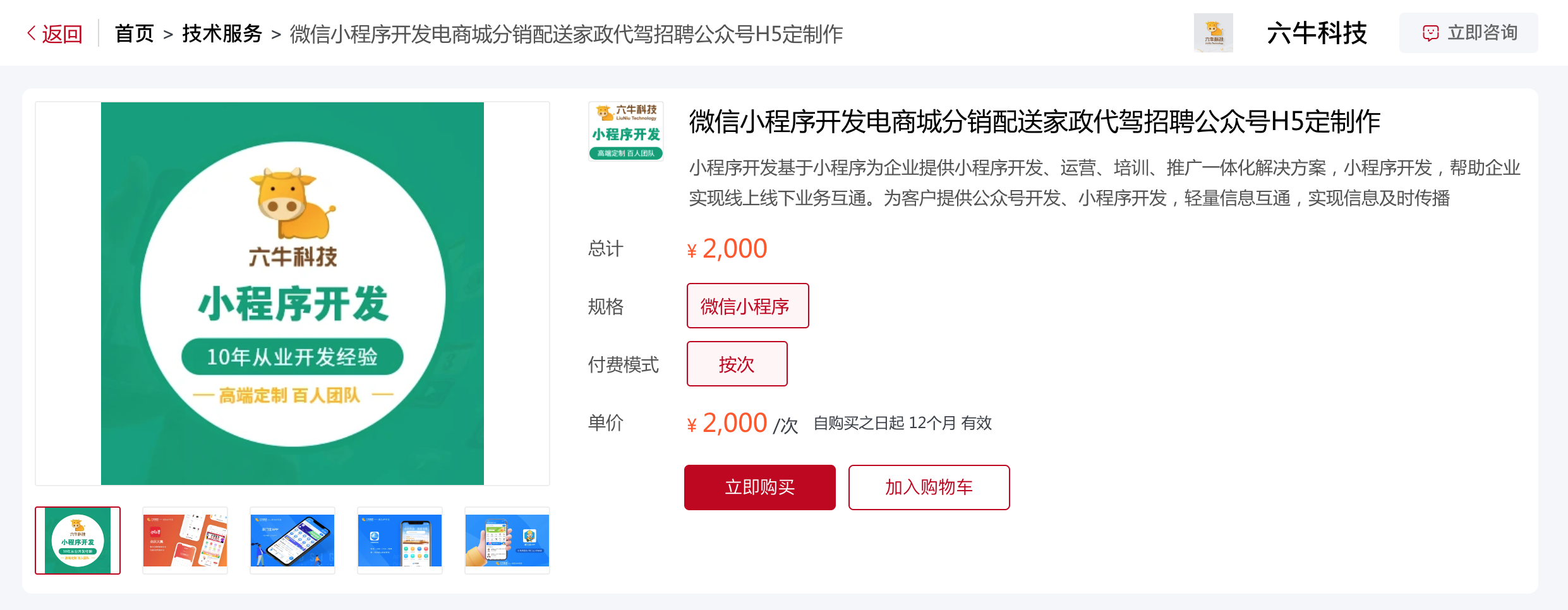
技术服务,提供了技术方案咨询、程序研发等众多服务。
大模型部署
小狗屁在体验专区,免费下单了 500 卡时的 GPU 资源,在部署大模型之前,打算先按照教程体验一下免费购买的 ChatGLM 软件应用,熟悉平台操作。
ChatGLM 体验
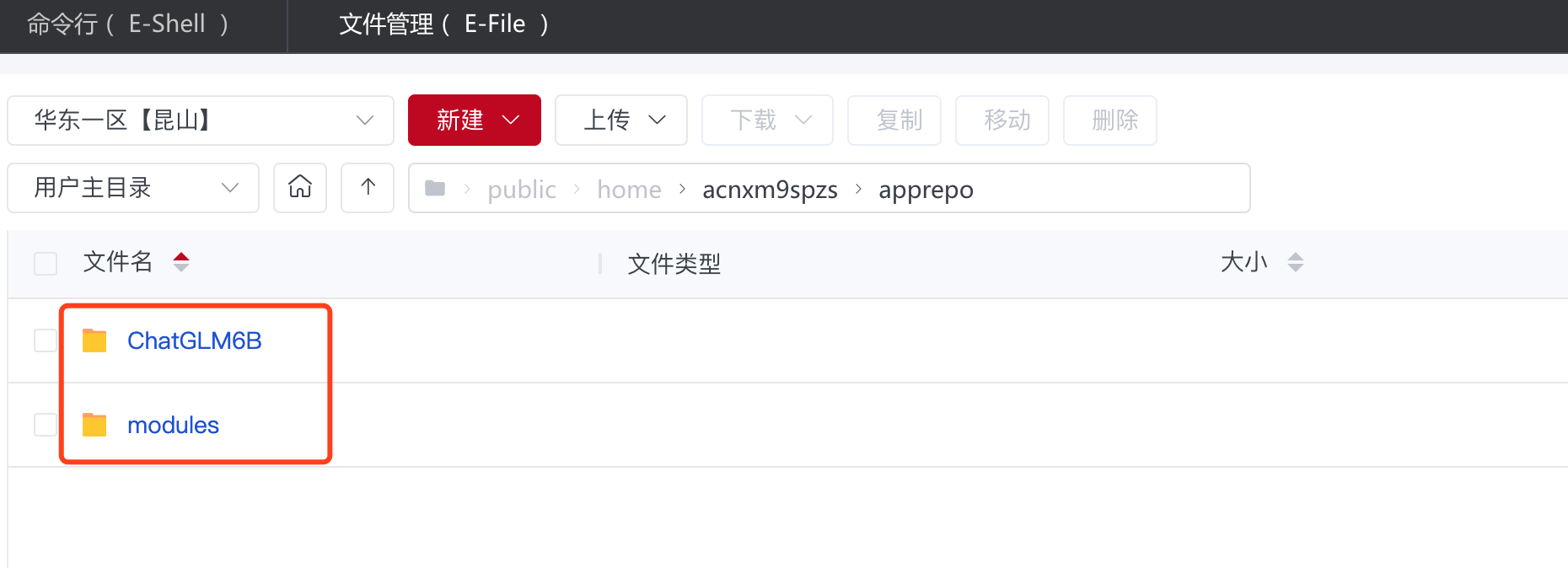
下单完成后,在数据管理的文件管理中,新增了 apprepo 文件夹,里面是该模型的工程文件
|—— apprepo
│ ├── modules # 环境管理工具
│ ├── ChatGLM6B/1.0-dtk23.04
| | |── app # 应用主体和依赖库
│ | | ├── . . .
| | ├── case # 可运行算例、脚本
│ | | ├── jsy_train.slurm # slurm 脚本文件
│ | | ├── slurm-7016471.out # 运行日志
│ | | └── . . .
| | ├── install.log # ChatGLM 安装日志
| | └── scripts # 应用环境变量
├── env.sh
└── post.sh
进入命令行,根据教程,尝试用以下命令,简单训练模型,并查看结果。
cd ~/apprepo/ChatGLM6B/1.0-dtk23.04/case
whichpartition # 查看可用队列
...
vi jsy_train.slurm # 更改队列为上行命令查到的可用队列
...
sbatch jsy_train.slurm # 提交作业
Submitted batch job 53980757
squeue # 查询作业运行状态
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
53980757 kshdtest ChatGLM xxxx R 0:13 2 e10r3n[08-09]
使用 sbatch 命令提交作业后,也可以在页面上查询到作业状态:
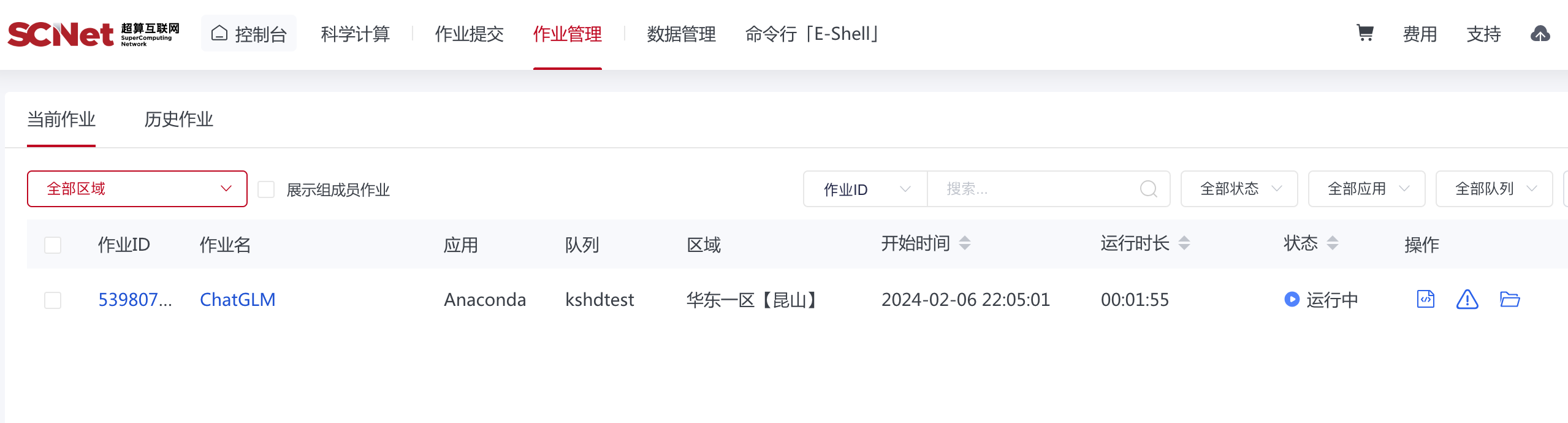
至于结果,自然是完全看不懂(甚至不确定是不是失败了 😅)
tail -f 53980757.out # 查看训练结果文件
I0206 22:07:44.685047 5390 ProcessGroupNCCL.cpp:837] [Rank 5] NCCL watchdog thread terminated normally
I0206 22:07:44.686949 4565 ProcessGroupNCCL.cpp:837] [Rank 4] NCCL watchdog thread terminated normally
I0206 22:07:44.687130 5387 ProcessGroupNCCL.cpp:837] [Rank 4] NCCL watchdog thread terminated normally
--------------------------------------------------------------------------
mpirun detected that one or more processes exited with non-zero status, thus causing
the job to be terminated. The first process to do so was:
Process name: [[32314,1],0]
Exit code: 135
大模型部署
现成的大模型搞不明白,还是重新完整体验一轮吧。这次选择部署的大模型,是目前开源的百川大模型,且它的最新版本为 Baichuan2。
项目结构
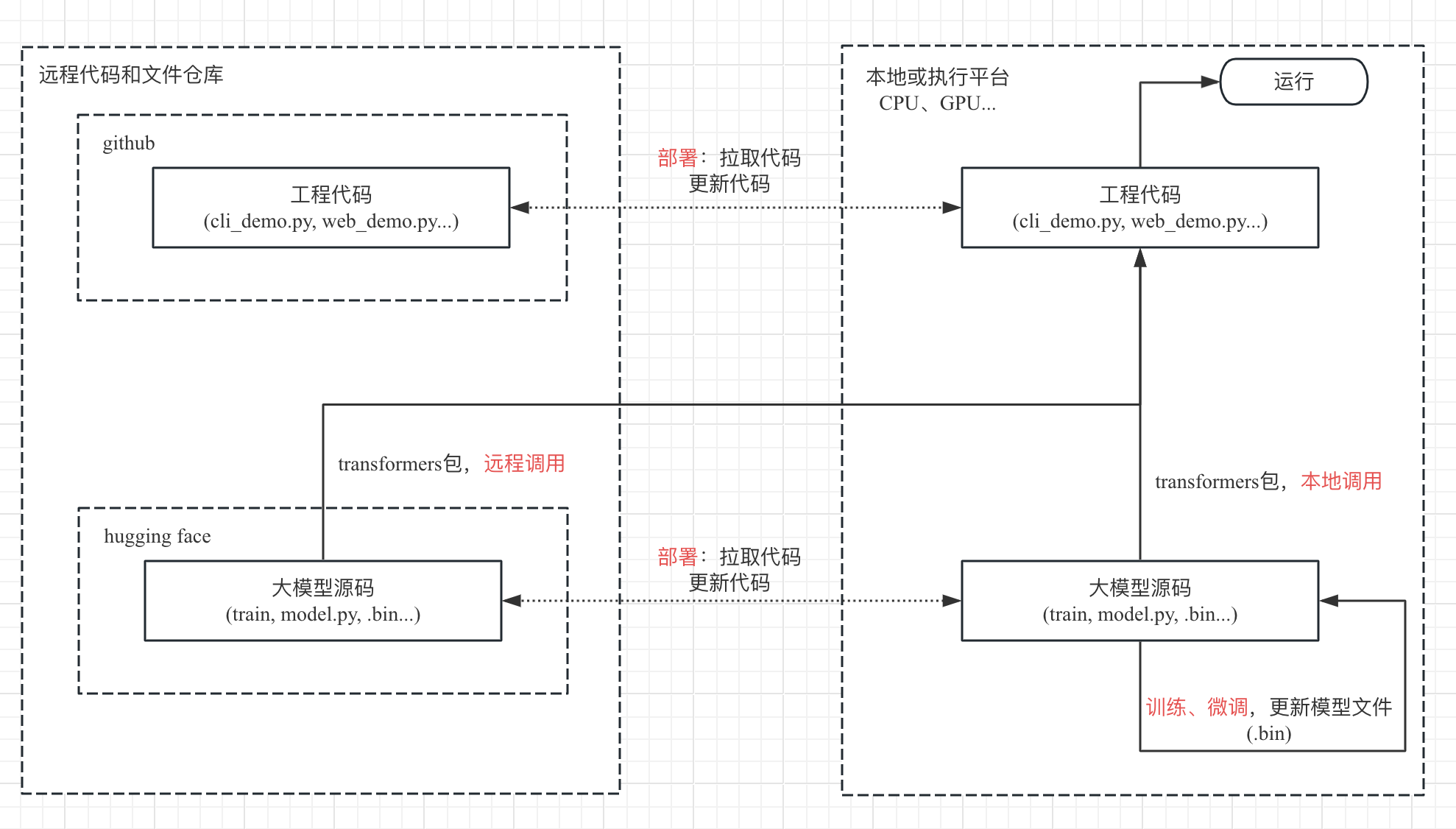
目前常用的大模型项目的流程,代码结构和调用逻辑可以总结为:
- 大模型源码 -> 工程代码部署 -> 训练大模型得到模型文件 -> 部署大模型 -> 运行模型(命令行、web 服务、API 接口等)-> 微调。
- 工程代码、模型应用等代码位于 github;模型源码、模型文件等数据位于 hugging face(核心是 .bin 的模型参数数据);工程代码与模型间的调用基于 transformers 框架进行。

通过流程图来展示,近似如下:
部署和命令行调用
本次打算先跳过训练和微调部分,部署思路如下:
- 在平台上,从 github 拉取工程代码。
- 在平台上,从 hugging face 拉取模型文件。
- 代码中的 transformers 框架调用时,调整模型文件地址为本地。
- 在平台上,配置 torch 环境和项目环境,用命令行调用本地的模型,查看结果。
mkdir LLM && cd LLM
## 1 从 github 拉取工程代码
git clone https://github.com/baichuan-inc/Baichuan2.git
...
cd Baichuan2
## 2 从 hugging face 拉取模型文件
mkdir models && cd models
# 网络问题,无法直接源站拉取 git clone https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat
# 从镜像站 clone
git clone https://hf-mirror.com/baichuan-inc/Baichuan2-7B-Chat
...
cd Baichuan2-7B-Chat
# 涉及LFS大文件限额,git-lfs存在收费问题,.bin 文件单独下载
wget -O pytorch_model.bin --no-check-certificate https://hf-mirror.com/baichuan-inc/Baichuan2-7B-Chat/resolve/main/pytorch_model.bin?download=true
wget -O tokenizer.model --no-check-certificate https://hf-mirror.com/baichuan-inc/Baichuan2-7B-Chat/resolve/main/tokenizer.model?download=true
## 3 修改调用的代码,模型文件地址设置为本地
cp cli_demo.py cli_chat_7B.py
vi cli_chat_7B.py
...
print("init model ...")
model = AutoModelForCausalLM.from_pretrained(
"./models/Baichuan2-7B-Chat", # 地址修改为本地,相对地址
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
model.generation_config = GenerationConfig.from_pretrained(
"./models/Baichuan2-7B-Chat" # 地址修改为本地,相对地址
)
tokenizer = AutoTokenizer.from_pretrained(
"./models/Baichuan2-7B-Chat", # 地址修改为本地,相对地址
use_fast=False,
trust_remote_code=True
)
...
## 4 调用模型,实验结果
# 在超算互联网平台上会出现卡顿 python3 cli_chat_7B.py
实际进行到第 4 步,直接运行 cli_chat_7B 文件,会一直卡顿。
原因是在 HPC(高性能计算)平台,对于共享型资源来说,平台并不是很推荐直接运行程序占用资源,而是需要通过 slurm 调度工具 提交计算任务,待得到资源后自动进行处理。因而该平台很适合无人工参与的耗时的大模型训练任务(会在后续篇章中继续探索),而部署和推理主要涉及不断接受用户的实时提问和进行实时回答,并不适合提交任务等待处理的方式。
但也有折中方案,即实时申请资源,然后登录到远程节点,并实时进行处理(针对远程节点没有 python3 的环境,可以联系平台客服解决 ^_^,帮忙在云存储上部署 miniconda3 和 torch2.1 等环境;或者自行去 /public/software 目录下寻找和安装)。
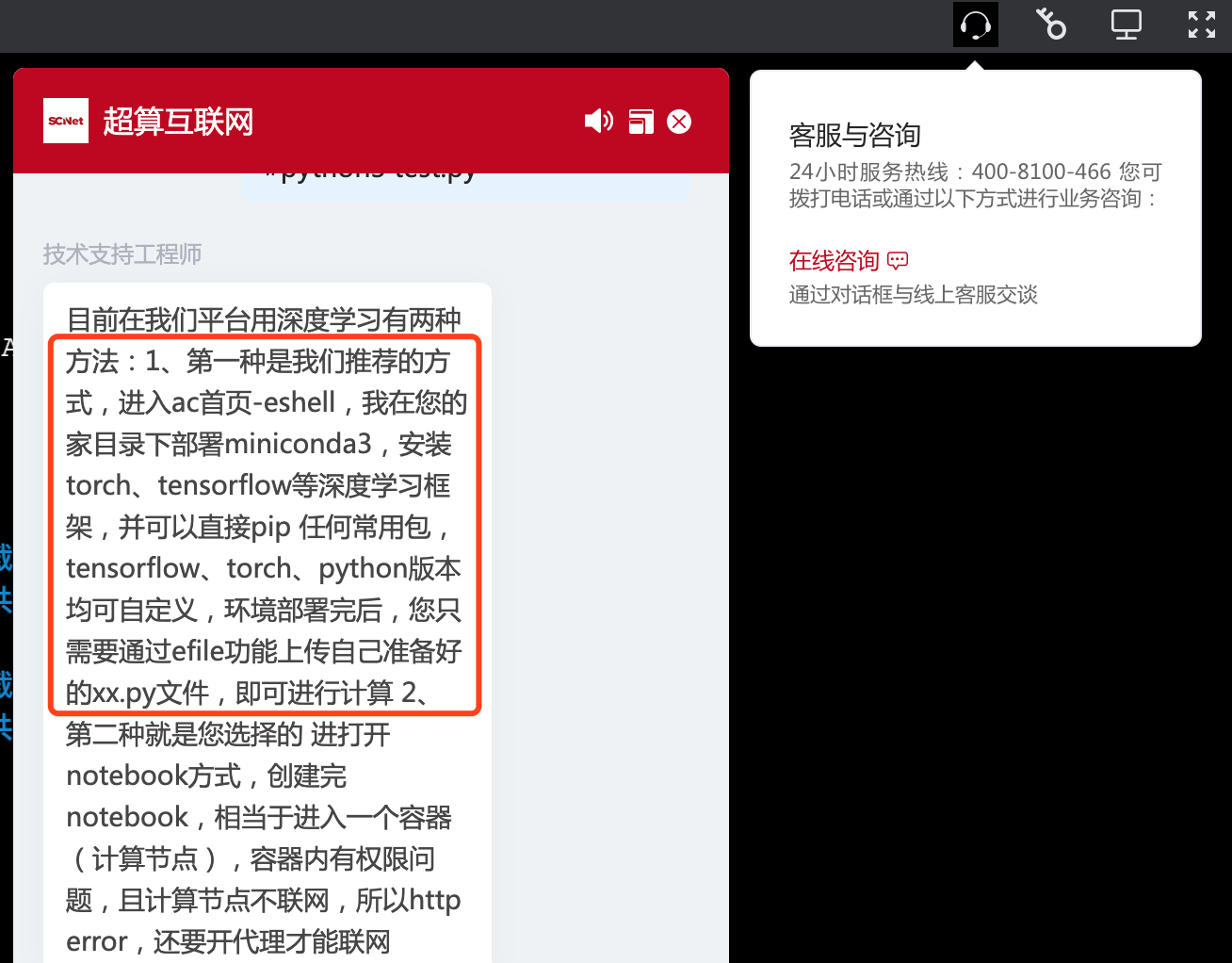
如果自行安装miniconda3的话,按照下列操作来:
# 安装 miniconda3
cp -r /public/software/apps/DeepLearning/whl/Miniconda/Miniconda3-py39_4.10.3-Linux-x86_64.sh ~/
mkdir -p ~/miniconda3/
bash Miniconda3-py39_4.10.3-Linux-x86_64.sh -b -f -p "~/miniconda3/"
rm -rf Miniconda3-py39_4.10.3-Linux-x86_64.sh
# 配置torch2.1环境
~/miniconda3/bin/conda create -n torch2.1_dtk23.10_py3.8 python=3.8
module load compiler/dtk/23.10
source ~/miniconda3/bin/activate torch2.1_dtk23.10_py3.8
export LD_LIBRARY_PATH=~/miniconda3/envs/torch2.1_dtk23.10_py3.8/lib:$LD_LIBRARY_PATH
pip3 install /public/software/apps/DeepLearning/whl/dtk-23.10/pytorch/torch2.1/torch-2.1.0a0+git793d2b5.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl
安装完 python3 和 torch 等环境后,接下来,继续第 4 步。这里原本踩了个坑,花了半小时缓慢运行了一次,才发现没有测试 torch 版本和 GPU 的匹配性,实际上是因为在使用 CPU 进行运算。
## 4.1 torch 和 GPU 匹配测试
# 准备好加载 python3.8 和 torch2.1 环境的命令,目前平台最高支持到 2.1
vi load_torch2.1_py3.sh
module load compiler/dtk/23.10
source ~/miniconda3/bin/activate torch2.1_dtk23.10_py3.8
export LD_LIBRARY_PATH=~/miniconda3/envs/torch2.1_dtk23.10_py3.8/lib:$LD_LIBRARY_PATH
chmod 764 load_torch2.1_py3.sh # 本人可执行
# 准备好 GPU 测试代码
vi test_gpu.py
import torch
print(torch.cuda.is_available())
# 申请作业资源,一般核卡比为 8:1
whichpartition
...
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 在节点上配置 python3 指令环境
source load_torch2.1_py3.sh
# 检查 GPU 和 python 是否能运行 GPU
rocm-smi # 该平台上,类似 nvidia-smi 的命令,查看 GPU 数据
python3 test_gpu.py
True # 结果若为 False,说明没有利用起 GPU,找客服安装合理的 torch 版本 ^_^;
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
确认能调用 GPU,说明环境配置没问题。接下来便可以开始安装项目环境,以及运行大模型。
## 4.2 远程节点无网环境,因此需要本地配置 python 依赖包的环境
# 配置指令环境
source load_torch2.1_py3.sh
# 配置 python 依赖包环境,使版本与 torch 相匹配
vi LLM/Baichuan2/requirements.txt
...
xformers==0.0.22 # xformers 需要降版本与 torch 版本相匹配
# 安装依赖包
pip3 install -r LLM/Baichuan2/requirements.txt
# 虽然需要的版本为 torch2.0.1,但 pip 会认为平台的 torch2.1 版本不够,进而覆盖更新
# 若 torch 被改变了版本,重新安装一次
pip3 install /public/software/apps/DeepLearning/whl/dtk-23.10/pytorch/torch2.1/torch-2.1.0a0+git793d2b5.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl
## 4.3 开始运行大模型
# 申请资源,一般核卡比为 8:1
whichpartition
...
salloc -p ${partition}$ -N 1 -n 16 --gres=dcu:2
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 配置指令环境
source load_torch2.1_py3.sh
# 运行程序
cd LLM/Baichuan2
python3 cli_chat_7B.py
init model ...
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
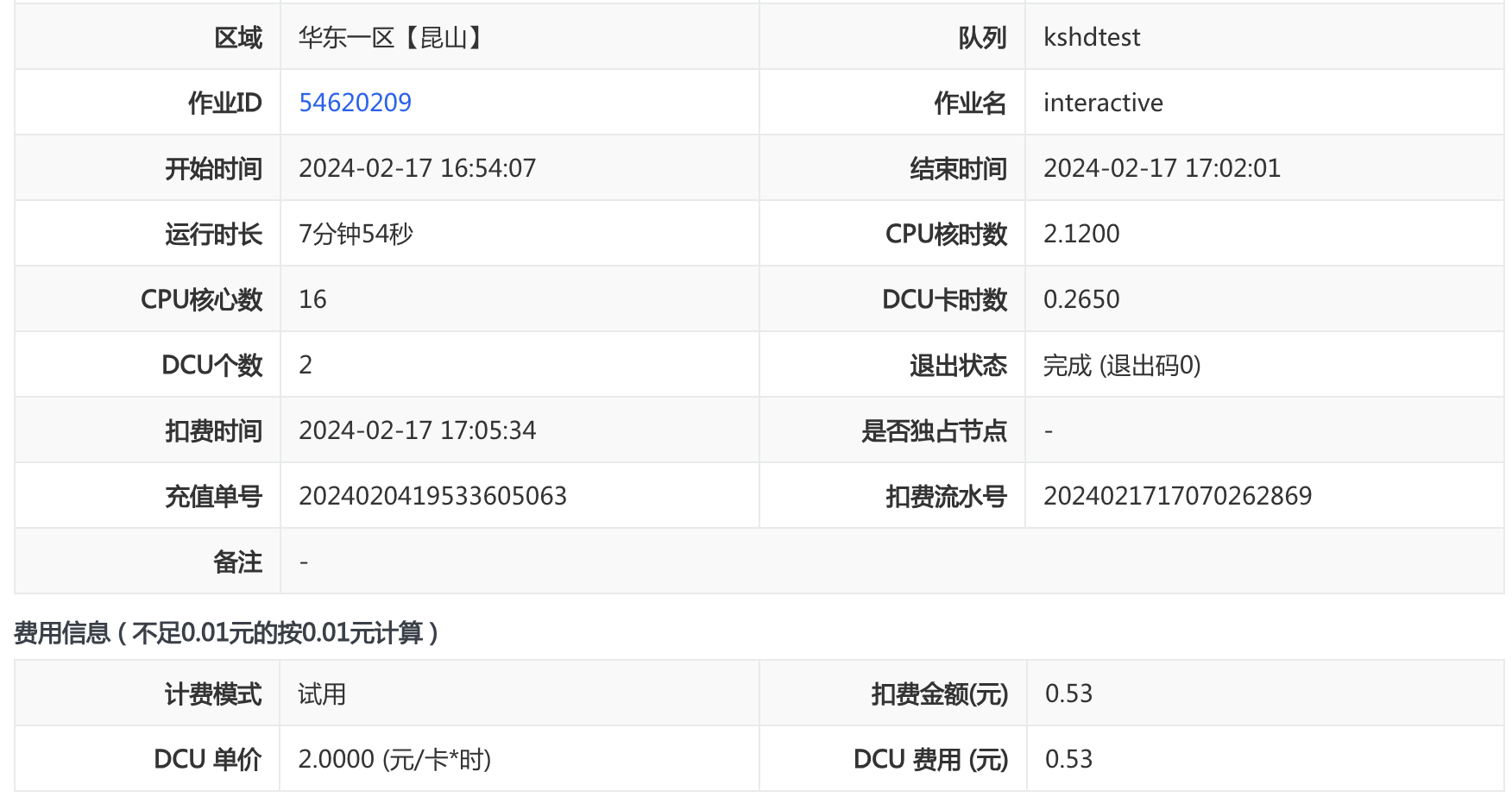
运行程序后,大约等 2-3 分钟,会进入到会话环节;简单提问之后,基本上无卡顿输出结果(首次回答可能会有 1 分钟左右的延迟)。
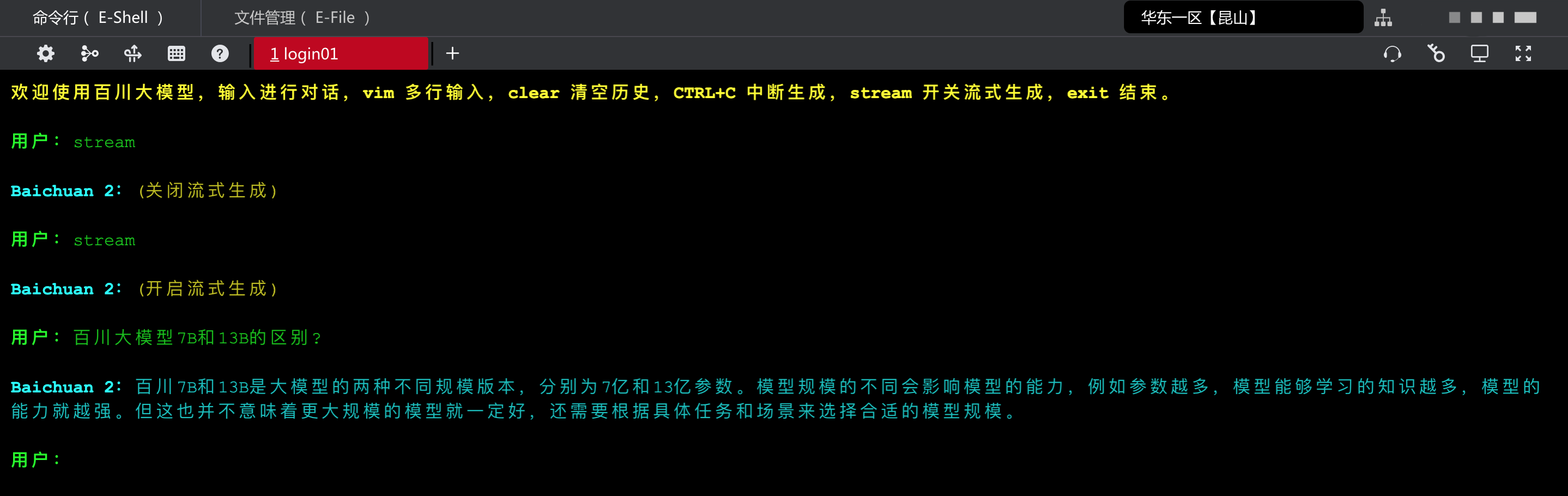
从理论上的账单来看,按卡时来算,$8min * 2卡 * 2元/卡时 = 0.5元 $。
总 结
总的来说,超算互联网平台提供了较为完善的算力基础设施服务。而本次,小狗屁成功在该平台探索了大模型的部署和运行流程。
值得注意的是,该平台的 GPU 使用方式,与传统的 NVIDIA-CUDA-torch 存在差异。因而需要联系客服,安装平台特殊版本的 torch 环境(默认的 torch 环境,会因为调用 GPU 失败,使用 CPU 进行缓慢的运行)。
而程序运行时,也发现了跟 xformers (用于训练加速的框架)有关的警告,这可能是 xformers 和 平台特殊版本的 torch 环境之间存在不兼容,将会在后续的大模型训练和微调的探索中继续去解决。