大模型,小探索 —— 在 16G 的 AMD 上搞微调有多作死?(入坑篇)
微信公众号内容地址: https://mp.weixin.qq.com/s/JsGoshZJKnbd-tdIA8B9KA
预训练和微调: 预训练类比于通识教育,侧重通用能力,提高模型的上限,如能更好地学习;微调类比于专业教育,侧重细节能力,弥补模型的下限,如能更好地干活。
继”熟练”掌握了大模型部署技术后,小狗屁已经摆烂数日,直到某天邮箱收到了一条信息:

既然算力已经到账,那就再探索一波,小试一下微调吧。
鉴于篇幅较长,在此先说结论: 在失败了一万次之后 😂,个人觉得,下一次一定能成功!

环境背景
先来梳理一下,目前为止的基本环境:
- 算力和存储: 超算互联网平台,非 NVIDIA 的 GPU(推测是 AMD-ROCm),以及特殊版本的 pytorch。
- 文生文大模型: Baichuan2,且之前已经在平台上部署了 Baichuan2-7B-Chat
- Github 地址: https://github.com/baichuan-inc/Baichuan2
- Hugging Face 地址: https://hf-mirror.com/baichuan-inc/Baichuan2-7B-Chat
- 文生文数据集: 目前暂未涉及,一般分为训练集、验证集和评测集。
微调理论
大模型微调(Fine-tuning)是指在已经预训练好的大型语言模型基础上,使用特定的数据集进行进一步的训练,以使模型适应特定任务或领域。通俗的理解,微调就是让通用的大模型具备更强的专业能力。
一般来说,与训练类似,微调的操作步骤包括:
- 目标数据集,微调需要使用的训练集、验证集和评测集。
- 目标基础模型
- 微调策略,如全微调、轻量级微调。
- 超参数,如学习率、批量大小、训练轮数等。
- 初始化模型参数,固定一部分现有模型参数 或者 全部修改训练。
- 进行微调训练
- 模型评估和调优,包含了专业能力测试和通识能力测试。
-
专业能力测试: 学习 $X$ 内容,考 $X$ 内容
。侧重于考察对专业内容的掌握,主要在微调阶段进行,验证微调效果。
-
通识能力测试: 学习 $X$ 内容,考 $X'$ 内容
。侧重于考察内容对通用能力的提升,如记忆力、阅读理解、逻辑推理等。主要在预训练阶段进行,验证训练效果;微调阶段主要是验证,专业度的提升没有很严重的影响模型的基础能力。
- 测试模型性能
- 模型部署和应用
微调实验
Baichuan2 的官方 Readme 提供了微调的样例,因此第一步先按照教程,跑通样例(实际上也卡在了第一步 😭)。
source load_torch2.1_py3.sh
# 1. 安装环境,包括 DeepSpeed
cd LLM/Baichuan2/fine-tune/
pip3 install -r requirements.txt
## torch 可能被覆盖,重新安装
pip3 install /public/software/apps/DeepLearning/whl/dtk-23.10/pytorch/torch2.1/torch-2.1.0a0+git793d2b5.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl
# 2. DeepSpeed 脚本
vi fine_tune_train.sh
''' 文件内容
hostfile=""
# deepspeed
# --num_gpus,不设置默认会用可见的所有GPU;
# --data_path,数据集路径;
# --model_name_or_path,模型路径;
# --output_dir,输出路径;
# --tf32,非 NVIDIA 的 GPU,暂时先设置 False
deepspeed --hostfile=$hostfile fine-tune.py \
--report_to "none" \
--data_path $1 \
--model_name_or_path $2 \
--output_dir $3 \
--model_max_length 512 \
--num_train_epochs 4 \
--per_device_train_batch_size 16 \
--gradient_accumulation_steps 1 \
--save_strategy epoch \
--learning_rate 2e-5 \
--lr_scheduler_type constant \
--adam_beta1 0.9 \
--adam_beta2 0.98 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--logging_steps 1 \
--gradient_checkpointing True \
--deepspeed ds_config.json \
--bf16 True \
--tf32 False \
--use_lora False
'''
chmod 764 fine_tune_train.sh
# 3. 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 16 --gres=dcu:2
salloc -p ${partition} -N 1 -n 16 --gres=dcu:2
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/Baichuan2/fine-tune/
./fine_tune_train.sh "data/belle_chat_ramdon_10k.json" "../models/Baichuan2-7B-Chat" "output"
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
运行 DeepSpeed 指令后,大概等 1 分钟,页面上开始有内容不断输出。然后接着出现报错,内容为显存不足(目前平台上免费的 DCU 的显存约为 16G/个)。

询问 GPT,查找解决方案如下:

数据并行
进一步询问 GPT,并尝试在 batch_size 的配置上进行尝试。

通过将 batch_size 调整为 8、4、1,以及 DCU 也尝试调整为 2、3、4 个,遗憾的是结果均为 OOM(out of memory),只能继续找别的方案。
另一方面,也可以使用如下的最简数据集进行测试。
vi LLM/Baichuan2/fine-tune/data/test.json
''' 文件内容
[{
"id": "27684",
"conversations": [
{
"from": "human",
"value": "你好,请问你能帮我查一下明天的天气吗?\n"
},
{
"from": "gpt",
"value": "当然,你在哪个城市呢?\n"
},
{
"from": "human",
"value": "我在上海。\n"
},
{
"from": "gpt",
"value": "好的,根据天气预报,明天上海多云转阴,气温在20到25摄氏度之间。需要我帮你查询其他信息吗?"
}
]
}]
'''
同样的,结果也显示 OOM 的报错,可以小结,数据层面上的优化暂时效果不大。再回头来进行理论分析,7B 的模型,仅加载和存储参数,基本就消耗了 10G 左右的显存,训练本身也会有临时存储的消耗,因而相比起来,数据集应该不是主要影响点。
模型并行
询问 GPT 模型并行的内容,可知目录下的 ds_config.json 即为 DeepSpeed 的配置文件。

实验采坑后,发现 GPT 所说的 partition_weights 等配置其实并不支持,DeepSpeed 主要是使用了 ZeRO(Zero Redundancy Optimizer)零冗余优化器来减少显存消耗。
# 零优化配置,阶段3 + 卸载
cd LLM/Baichuan2/fine-tune
vi ds_config.json
''' 文件内容
...
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
'''
vi fine_tune_train.sh
''' 文件内容
...
--num_train_epochs 1 \
--per_device_train_batch_size 4 \
--logging_steps 4 \
--bf16 False \
'''
# 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 16 --gres=dcu:2
salloc -p ${partition} -N 1 -n 16 --gres=dcu:2
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/Baichuan2/fine-tune
./fine_tune_train.sh "data/test.json" "../models/Baichuan2-7B-Chat" "output"
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
运行后,似乎没有出现 OOM 报错,但发现了新的异常。

查看 lib 目录下的 torch 文件夹,最终找到 version.py。该平台的 torch 包的cuda 值为 None,进而导致外层调用报错(到哪都是熟悉的 NPE 问题 😭)。
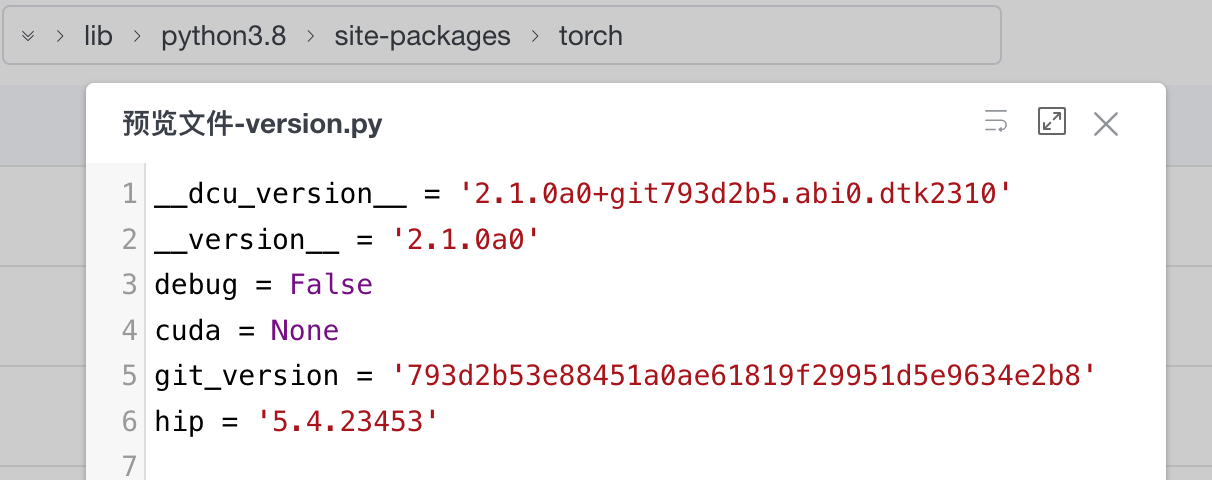
抱有一丝侥幸,暂时不打算更改源码,继续探讨别的解决方案。
LoRA 轻量级微调
按照教程,Baichuan2 的微调也支持了 LoRA(Low-Rank Adaptation of Large Language Models)技术,因此打算试一波。
source load_torch2.1_py3.sh
# 1. 安装环境,peft
pip3 install peft
# 2. DeepSpeed 脚本
cd LLM/Baichuan2/fine-tune/
vi fine_tune_train.sh
''' 文件内的内容
...
--use_lora True
'''
# 3. 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 16 --gres=dcu:2
salloc -p ${partition} -N 1 -n 16 --gres=dcu:2
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/Baichuan2/fine-tune
set PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:32
./fine_tune_train.sh "data/test.json" "../models/Baichuan2-7B-Chat" "output"
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
从结果上来看,尽管规避了 OOM 的问题,但遇到了一样的报错,即 torch 包与其他工具不兼容。

LLaMA Factory
https://github.com/hiyouga/LLaMA-Factory,无奈之下,小狗屁意外找到了一个新的平台,帮忙集成了预训练、微调、推理等操作,同时看报告也有省显存、省时间的效果,因而打算试一试。
source load_torch2.1_py3.sh
# 1. 安装环境
cd LLM
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip3 install -r requirements.txt
# 2. 设置指令
vi sft_baichuan.sh
''' 文件内容
# 不使用 DeepSpeed 时,为单机单卡
CUDA_VISIBLE_DEVICES=0 python3 src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path ../Baichuan2/models/Baichuan2-7B-Chat \
--dataset alpaca_gpt4_en \
--template default \
--finetuning_type lora \
--lora_target W_pack \
--output_dir "output" \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
'''
chmod 764 sft_baichuan.sh
# 3. 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
./sft_baichuan.sh
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
同样的,虽然没有 OOM 的报错,但也还是遇到了兼容性问题。

兼容性问题处理
既然多次尝试都无法规避兼容性问题,那就只能着手处理了。
首先,明确问题为: DeepSpeed、LoRA、xFormers 等工具,与 AMD 显卡的 ROCm 系统存在局部的不兼容。
进一步用关键词 “xxx for rocm” 进行谷歌搜索,基本也都能找到一些兼容方案,或者是 AMD 官方也会 fork 项目之后进行适配。
DeepSpeed for ROCm + Baichuan2-fine-tune
DeepSpeed 的兼容策略主要是,直接修改源码,跳过验证;接着使用 Baichuan2 自身的微调代码进行实验。
source load_torch2.1_py3.sh
# 1. deepspeed for rocm,https://github.com/microsoft/DeepSpeed/issues/3091
# 修改源码,跳过验证
vi ~/miniconda3/envs/torch2.1_dtk23.10_py3.8/lib/python3.8/site-packages/deepspeed/ops/op_builder/builder.py
''' 文件内容
...
def assert_no_cuda_mismatch(name=""):
# ROCM 平台,跳过验证
if OpBuilder.is_rocm_pytorch():
return True
cuda_major, cuda_minor = installed_cuda_version(name)
'''
# 2. lora 完成适配前,关闭 lora
vi ~/LLM/Baichuan2/fine-tune/fine_tune_train.sh
''' 文件内容
...
--use_lora False
'''
# 3. 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 16 --gres=dcu:2
salloc -p ${partition} -N 1 -n 16 --gres=dcu:2
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/Baichuan2/fine-tune
./fine_tune_train.sh "data/test.json" "../models/Baichuan2-7B-Chat" "output"
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
结果发现不兼容的环节已经跳过去了,但是接下来又遇到了 OOM 的问题。因此,还得再借助 LoRA 的优化。
LoRA for ROCm + LLaMA-Factory
LoRA 的兼容策略主要是,底层的 bitsandbytes 使用低版本,不严格要求检测到 NVIDIA 的 GPU,带来的潜在问题可能是量化过程实际使用 CPU 进行操作;接着使用 LLaMa-Factory 的训练框架进行实验。
source load_torch2.1_py3.sh
# 1. LoRA for rocm,https://github.com/oobabooga/text-generation-webui/issues/3259
# 使用指定版本的 bitsandbytes
pip3 uninstall bitsandbytes
pip3 install bitsandbytes==0.38.1
# 2. 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
./sft_baichuan.sh
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
结果会发现,出现了 xFormers 相关的兼容性报错。
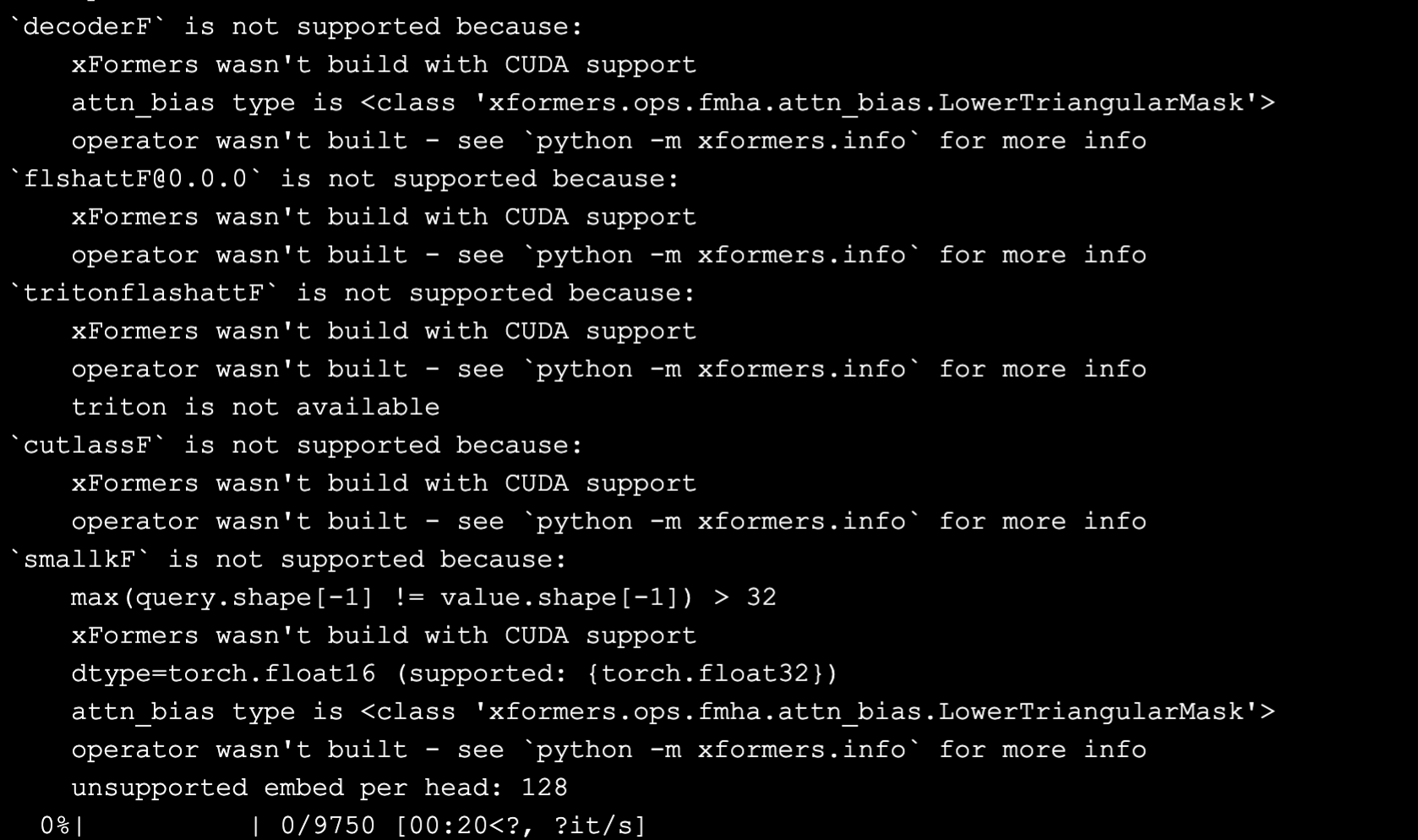
接下来,Baichuan2 的配置中开启 LoRA,也会走到 xFormers 的兼容性报错这。

xFormers for ROCm
总体思路是研究并使用 AMD 官方的适配版本,https://github.com/ROCm/xformers。具体细节,就下次再说吧。

总 结
主要面临的困难:
- GPU 的显存较小,仅 16 G。
- 非 NVIDIA 的 GPU(推测是 AMD-ROCm),以及对应的 pytorch,跟 DeepSpeed、LoRA、xFormers 等常用工具的不兼容。
主要解决方案:
-
针对显存较小,使用 LoRA、ZeRO 等微调方案,节省空间
。
- 针对不兼容,逐步处理,目前已经完成了 DeepSpeed、LoRA(bitsandbytes)的适配。
下一步计划:
- 解决 xFormers 不兼容的问题,完成单样例微调实验。
- 选择合适的数据集,进行一次微调实操。