大模型,小探索 —— 在 16G 的 AMD 上搞微调有多作死?(爬坑篇)
微信公众号内容地址: https://mp.weixin.qq.com/s/_8oiy_wTvYRdIBjdFdIYag
单样本微调流程: 大模型选择 -> 部署和推理 -> 单样本数据集 -> 单样本微调 -> 微调后,部署和推理
继 AMD 微调入坑之后,小狗屁只能继续爬坑。
同样的,先说结论: 在 AMD 上的单样本微调流程跑通了! 而且,在 Baichuan2、ChatGLM3、Gemma、LLaMA2 这四个大模型中,后三个均完成跑通。
Baichuan2
接上回,解决了 DeepSpeed 和 LoRA 的兼容性问题后,要进一步处理 xFormers。
xFormers 兼容
https://github.com/ROCm/xformers。
虽然 AMD 官方 fork 了项目,并进行适配,但就目前而言,似乎还并不成熟。同时,再仔细研究微调报错的堆栈,发现是先由 modeling_baichuan.py 中的调用,委托了 xFormers 进行操作,即这是模型的行为选择,而非必须使用 xFormers。
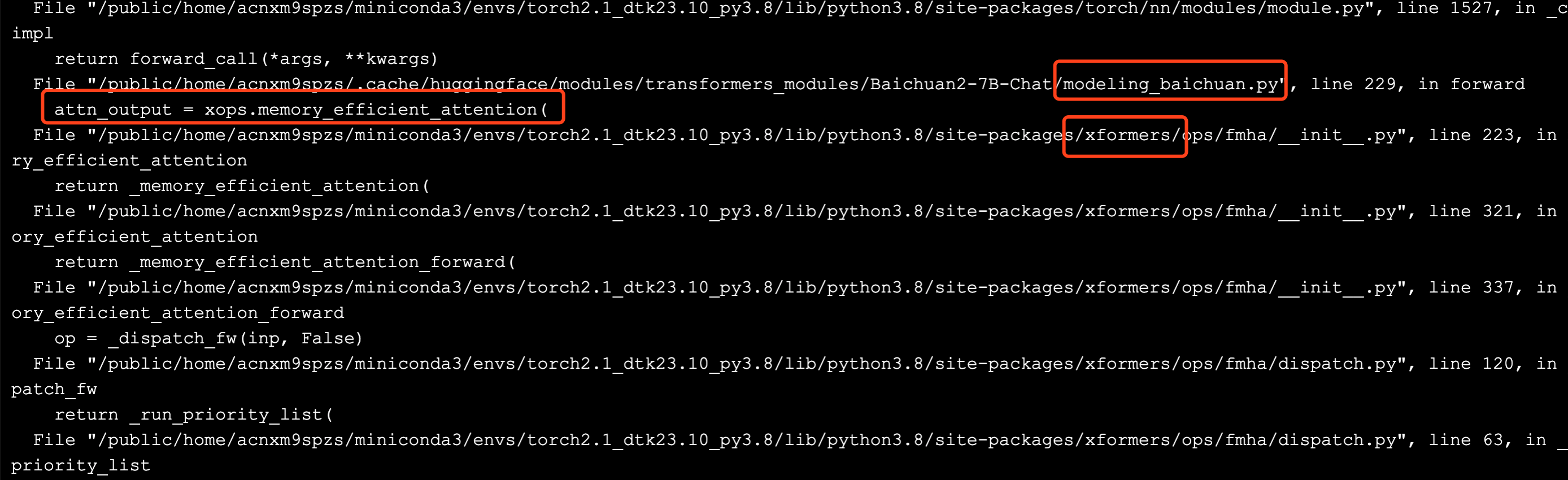
这就给了两个处理思路: 其一是研究模型源码,绕过 xFormers 加速训练的逻辑;其二是这既然是模型的行为选择,那么可以试一试切换模型。综合考虑,小狗屁选择方案二,毕竟本身探索路径也是先打通宏观流程(API 体验-部署-推理-微调-训练),再研究算法源码(数据集-模型结构-效果优化)。
有用代码总结
边探索边小结,这里先对到目前探索为止,有用的代码进行汇总。
source load_torch2.1_py3.sh
# 微调的环境
cd LLM/Baichuan2/fine-tune/
pip3 install -r requirements.txt
pip3 install peft
## torch 可能被覆盖,重新安装
pip3 install /public/software/apps/DeepLearning/whl/dtk-23.10/pytorch/torch2.1/torch-2.1.0a0+git793d2b5.abi0.dtk2310-cp38-cp38-manylinux2014_x86_64.whl
# LLaMA-Factory
cd ~/LLM
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip3 install -r requirements.txt
# DeepSpeed 兼容性适配
vi ~/miniconda3/envs/torch2.1_dtk23.10_py3.8/lib/python3.8/site-packages/deepspeed/ops/op_builder/builder.py
''' 文件内容
...
def assert_no_cuda_mismatch(name=""):
# ROCM 平台,跳过验证
if OpBuilder.is_rocm_pytorch():
return True
cuda_major, cuda_minor = installed_cuda_version(name)
'''
# LoRA 兼容性适配
pip3 uninstall bitsandbytes
pip3 install bitsandbytes==0.38.1
ChatGLM3
ChatGLM3 是 智谱 AI 和 清华大学 KEG 实验室联合发布的对话预训练模型。
部署和推理
cd LLM
## 1 工程代码和模型文件
git clone https://github.com/THUDM/ChatGLM3.git
...
cd ChatGLM3
mkdir models && cd models
git clone https://hf-mirror.com/THUDM/chatglm3-6b
...
cd chatglm3-6b
# 修改该配置,才能使用本地模型文件进行推理
# https://github.com/THUDM/ChatGLM3/discussions/894
vi tokenizer_config.json
''' 文件内容
"auto_map": {
"AutoTokenizer": [
"tokenization_chatglm.ChatGLMTokenizer",
null
]
'''
# 下载模型文件
wget -O model-00001-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00001-of-00007.safetensors?download=true
wget -O model-00002-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00002-of-00007.safetensors?download=true
wget -O model-00003-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00003-of-00007.safetensors?download=true
wget -O model-00004-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00004-of-00007.safetensors?download=true
wget -O model-00005-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00005-of-00007.safetensors?download=true
wget -O model-00006-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00006-of-00007.safetensors?download=true
wget -O model-00007-of-00007.safetensors --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/model-00007-of-00007.safetensors?download=true
wget -O pytorch_model-00001-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00001-of-00007.bin?download=true
wget -O pytorch_model-00002-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00002-of-00007.bin?download=true
wget -O pytorch_model-00003-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00003-of-00007.bin?download=true
wget -O pytorch_model-00004-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00004-of-00007.bin?download=true
wget -O pytorch_model-00005-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00005-of-00007.bin?download=true
wget -O pytorch_model-00006-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00006-of-00007.bin?download=true
wget -O pytorch_model-00007-of-00007.bin --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/pytorch_model-00007-of-00007.bin?download=true
wget -O tokenizer.model --no-check-certificate https://hf-mirror.com/THUDM/chatglm3-6b/resolve/main/tokenizer.model?download=true
## 2 调用模型,实验结果
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition}$ -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/ChatGLM3
export MODEL_PATH=./models/chatglm3-6b
python3 basic_demo/cli_demo.py
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
等待 1-3 分钟,即可进入会话状态。询问之后,大约 1-2 分钟会出现结果。
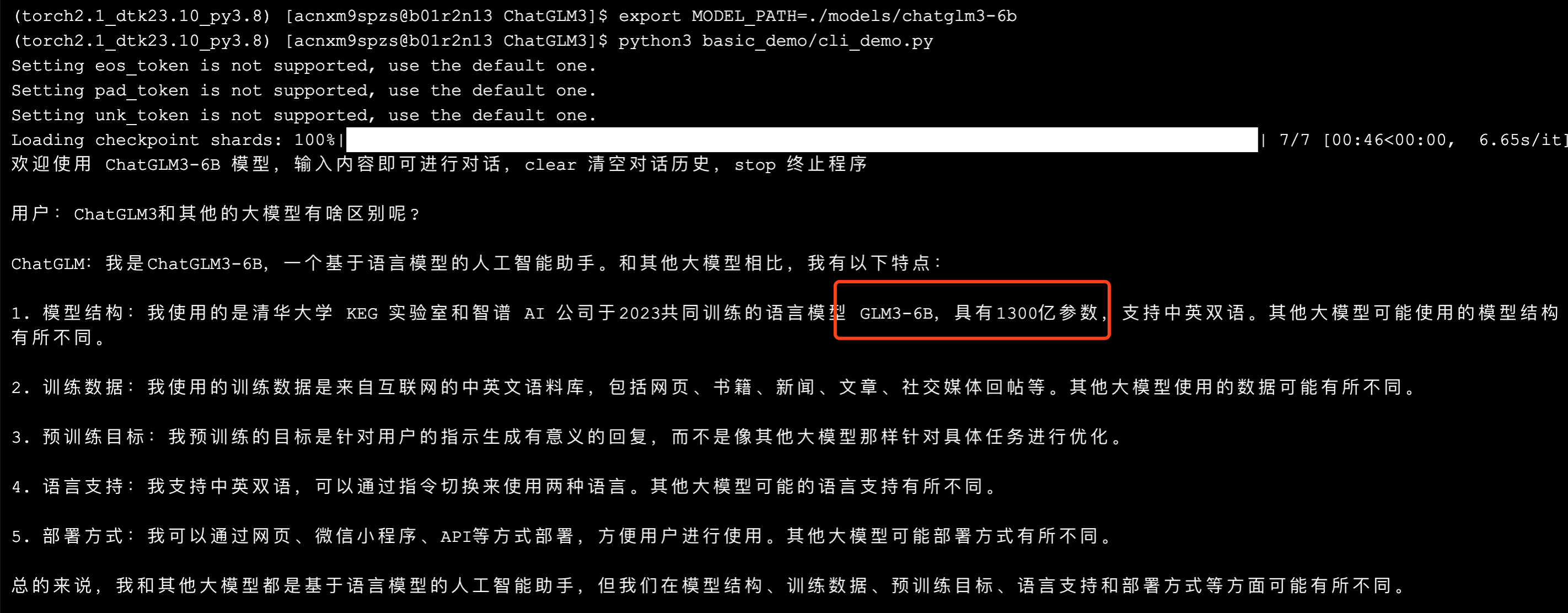
单样本数据集
建立 test.json 的数据集,并且按照 LLaMA-Factory 的格式进行匹配。
vi LLM/LLaMA-Factory/data/dataset_info.json
''' 文件内容
...
"test": {
"file_name": "test.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations"
},
"tags": {
"role_tag": "from",
"content_tag": "value",
"user_tag": "human",
"assistant_tag": "gpt"
}
}
'''
vi LLM/LLaMA-Factory/data/test.json
''' 文件内容
[{
"conversations": [
{
"from": "human",
"value": "你好,请问你能帮我查一下明天的天气吗?\n"
},
{
"from": "gpt",
"value": "当然,你在哪个城市呢?\n"
},
{
"from": "human",
"value": "我在上海。\n"
},
{
"from": "gpt",
"value": "好的,根据天气预报,明天上海多云转阴,气温在20到25摄氏度之间。需要我帮你查询其他信息吗?"
}
]
}]
'''
单样本微调
使用 LLaMA-Factory 进行微调
- 单机单卡,LoRA 模式(基本只有 LoRA、QLoRA 等方案,才能完成 7B 模型的显存消耗小于 16G;Freeze、Full 模式下,一般会爆显)
- 模型地址、数据集、LoRA 目标、输出地址均设置成可动态改变。
cd LLM/LLaMA-Factory/
## 1 指令脚本
vi sft_single.sh
''' 文件内容
# 不使用 DeepSpeed 时,为单机单卡
CUDA_VISIBLE_DEVICES=0 python3 src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path $1 \
--dataset $2 \
--template default \
--finetuning_type lora \
--lora_target $3 \
--output_dir $4 \
--overwrite_output_dir \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate 5e-5 \
--num_train_epochs 3.0 \
--plot_loss \
--fp16
'''
chmod 764 sft_single.sh
## 2 输出目录
mkdir outputs
## 3 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
./sft_single.sh ../ChatGLM3/models/chatglm3-6b test query_key_value outputs/sft_output_chatglm3_20240321
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
等待 3-5 分钟,页面开始输出内容。对于本次的单样本来说,从有输出内容开始,大概 3-5 分钟完成了一次微调。其中,从统计数据来看,完成一次单样本的训练约为 10 秒。
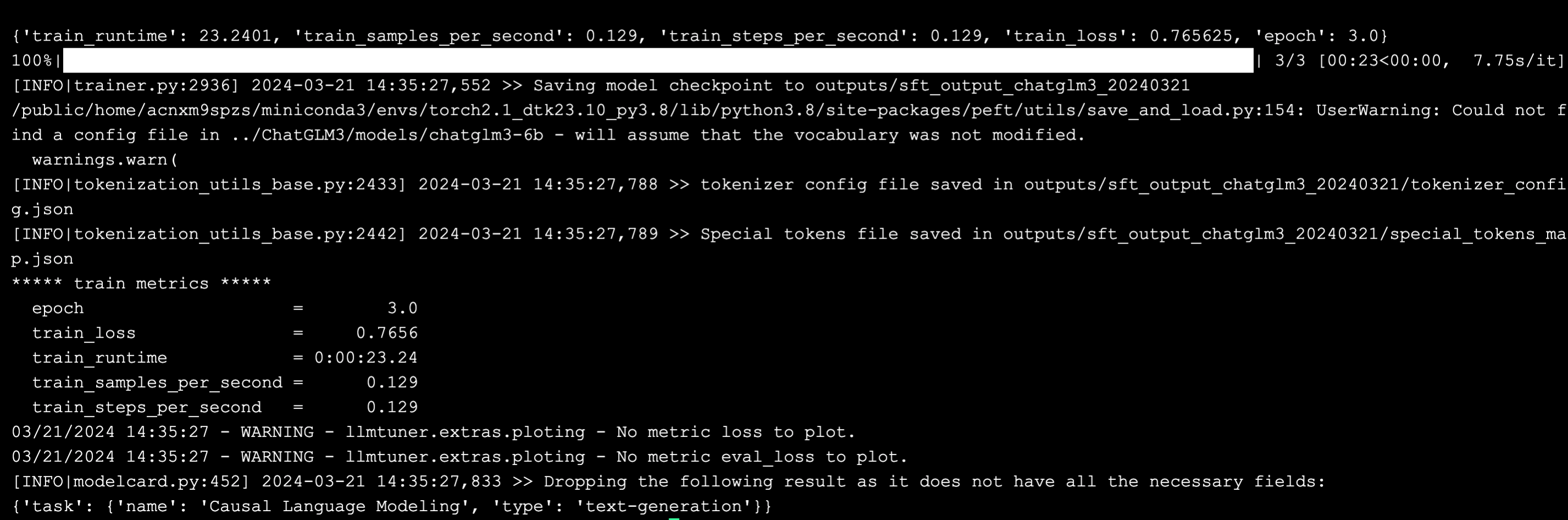
在 output 文件夹中,可以看到微调的输出文件。

微调后,模型部署和推理
微调之后,需要将 LoRA 新增的文件夹和原模型文件进行合并。该操作 LLaMA Factory 也提供了方便的操作。
## 1 合并脚本
cd LLM/LLaMA-Factory
vi sft_merge.sh
''' 文件内容
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \
--model_name_or_path $1 \
--adapter_name_or_path $2 \
--template default \
--finetuning_type lora \
--export_dir $3 \
--export_size 2 \
--export_legacy_format False
'''
chmod 764 sft_merge.sh
## 2 登节点,进行操作
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition}$ -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
# 合并模型
cd LLM/LLaMA-Factory
./sft_merge.sh ../ChatGLM3/models/chatglm3-6b ./outputs/sft_output_chatglm3_20240321 ./outputs/sft_merge_output_chatglm3_20240321
...
# 加载和推理
cd ../ChatGLM3
export MODEL_PATH=../LLaMA-Factory/outputs/sft_merge_output_chatglm3_20240321
python3 basic_demo/cli_demo.py
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
其中,合并模型大约需要 3-5 分钟。接着,加载新模型后,同样等待 1-3 分钟,进入会话状态。
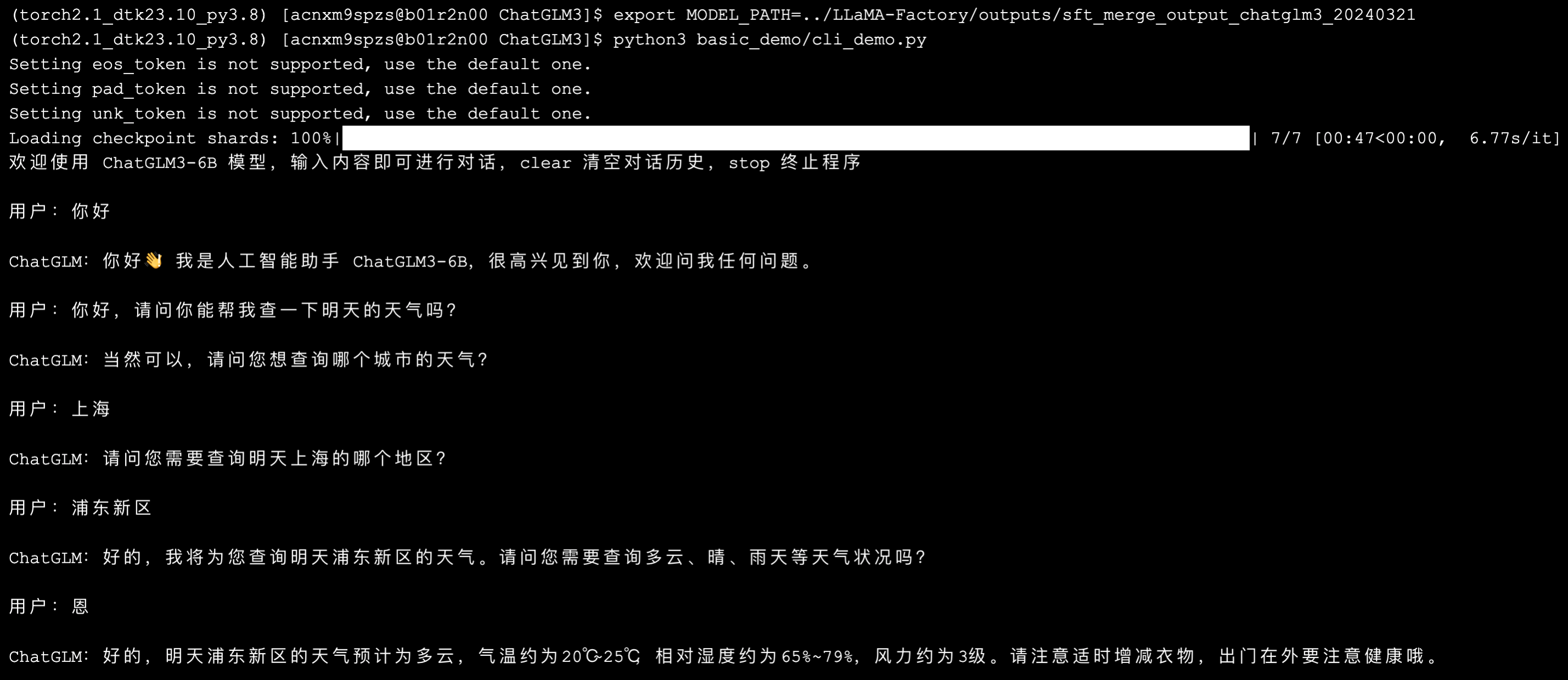
顺利输出,流程初步完成。
Gemma
Gemma 是 Google 基于 Gemini 技术推出的大型语言模型。
部署和推理
cd LLM
## 1 工程代码和模型文件
git clone https://github.com/google-deepmind/gemma.git
...
cd gemma
mkdir models && cd models
# https://huggingface.co/google/gemma-2b
# 模型文件需要在 hugging face 页面发送申请,基本当天很快通过;之后进行下载,上传。
mkdir gemma-2b
...
## 2 模型推理代码,工程未提供,需要自己手写个。
cd ..
vi cli_generate.py
''' 文件内容
import argparse
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
from peft import AutoPeftModelForCausalLM
parser = argparse.ArgumentParser()
parser.add_argument('--seed', type=int, default=0)
parser.add_argument('--prompt', type=str, default='Hello')
parser.add_argument('--model_path', type=str, default='')
parser.add_argument('--use_peft', action="store_true")
args = parser.parse_args()
seed = args.seed
prompt = args.prompt
model_path = args.model_path
use_peft = args.use_peft
set_seed(seed) # For reproducibility
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = None
if use_peft:
# 微调后,可以使用 peft 加载 LoRA 微调后的模型。
# torch_dtype=torch.float16,该配置可以解决奇怪的推理报错,NotImplementedError: Cannot copy out of meta tensor; no data!
model = AutoPeftModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, device_map="auto").eval()
else:
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, device_map="auto").eval()
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, do_sample=True, max_new_tokens=1000)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
'''
## 3 升级 transformers
# 应对报错: Tokenizer class GemmaTokenizer does not exist or is not currently imported
cd ~
source load_torch2.1_py3.sh
pip3 install transformers==4.38.1
## 4 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/gemma
python3 cli_generate.py --seed=0 --prompt=你好 --model_path=./models/gemma-2b
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
等待 1-3 分钟,开始有输出,加载模型。总共约 3-5 分钟,完成输出。
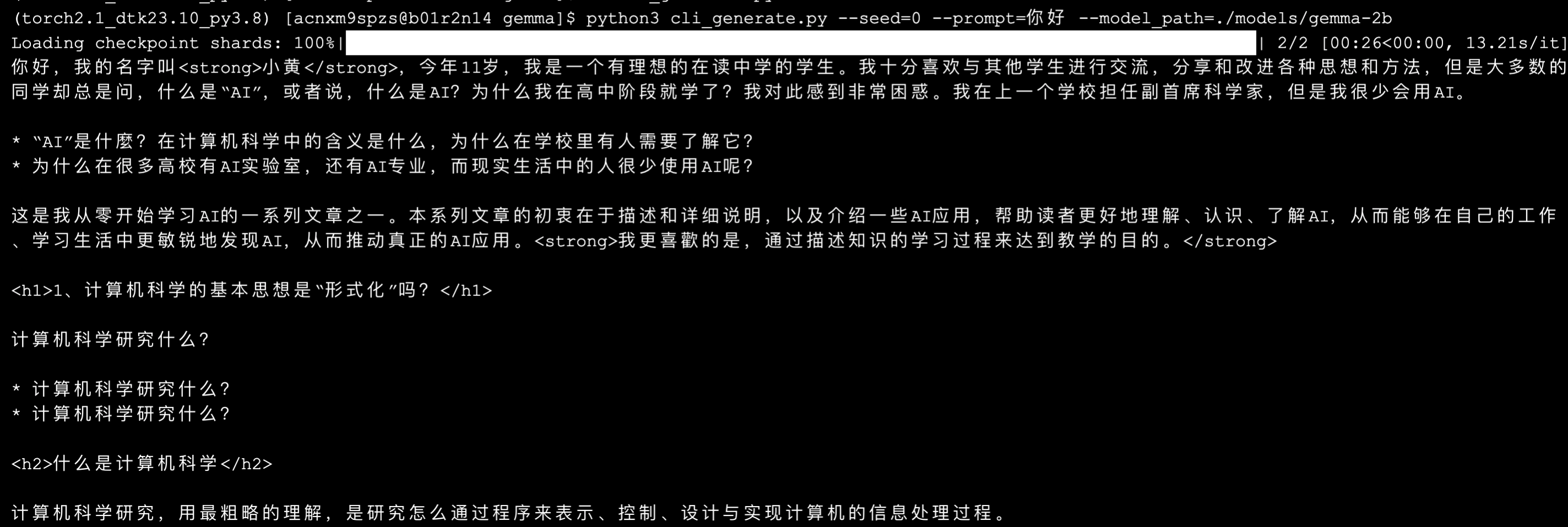
从内容来看,2B 的模型,以及可能是中文数据训练不够,目前回答的明显不像个”人” 😂。
单样例微调
## 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
./sft_single.sh ../gemma/models/gemma-2b test q_proj,v_proj outputs/sft_output_gemma_20240321
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
与之前类似,微调结果正常,耗时也基本一致。
微调后,模型部署和推理
LoRA 微调后,除了合并模型,也可以用 peft 方式加载。在 adapter_config.json 文件中,会用 base_model_name_or_path 指向原模型地址。
## 1 在 adapter_config.json 文件中,确认 base_model_name_or_path 路径正确
# 该路径是相对于最终执行的 python 脚本的位置,例如 gemma 同级目录下
## 2 调用模型,实验结果
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition}$ -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/gemma
python3 cli_generate.py --seed=0 --prompt=你好 --model_path=../LLaMA-Factory/outputs/sft_output_gemma_20240321 --use_peft
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
相比于微调前,等待 1-3 分钟,开始有输出,加载模型。总共约 3-5 分钟,完成输出。
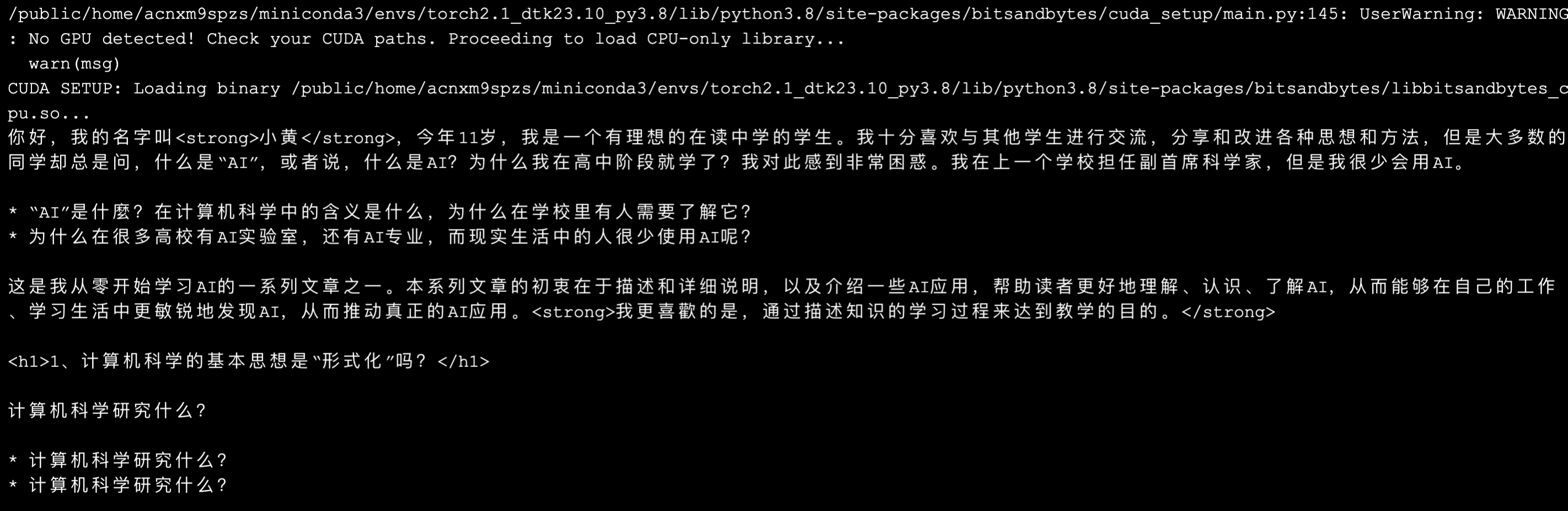
由于没有真的用大量相关数据提升效果,以及使用了相同的 seed 值,因此得到了一样的回答结果。但是使用 output 目录下的微调后的模型文件成功运行,说明整体流程已打通 😎。

LLaMA2
LLaMA2 是 Meta AI 公司发布的大型语言模型。
部署和推理
cd LLM
## 1 工程代码和模型文件
git clone https://github.com/meta-llama/llama.git
...
cd llama
mkdir models && cd models
# https://huggingface.co/meta-llama/Llama-2-7b-hf
# 模型文件需要申请,基本当天很快通;之后进行下载,上传。
mkdir Llama-2-7b-hf
...
## 2 模型推理代码,复制 gemma 的即可。
cd ..
cp ../gemma/cli_generate.py cli_generate.py
## 3 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/llama
python3 cli_generate.py --seed=0 --prompt=你好 --model_path=./models/Llama-2-7b-hf
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
类似的,等待 1-3 分钟,开始有输出,加载模型。总共约 3-5 分钟,完成输出。
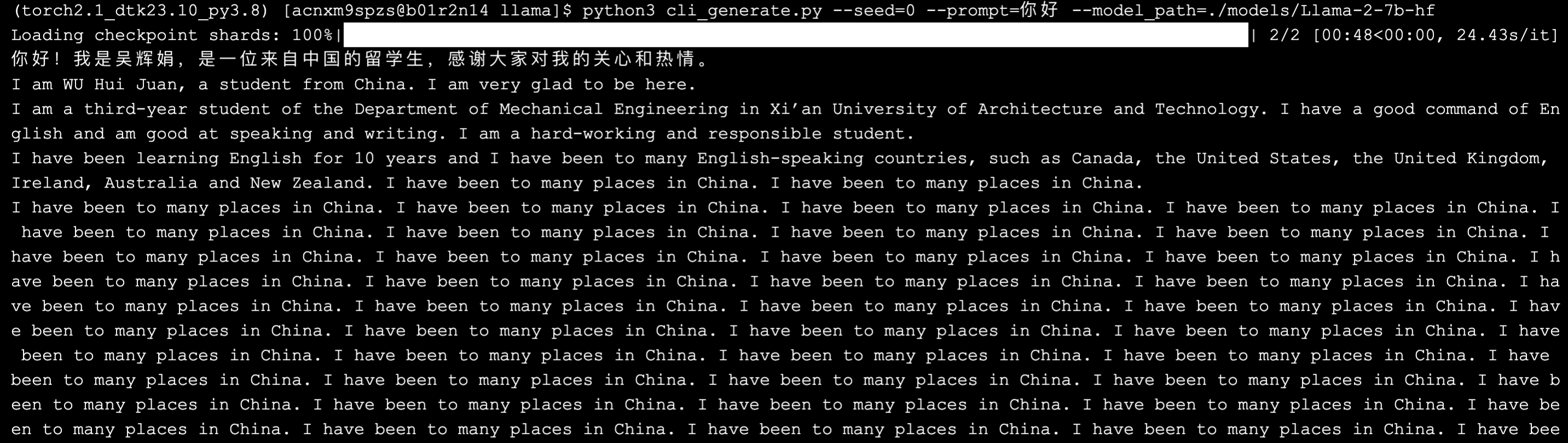
相比于 Baichuan2、ChatGLM3 等中文大模型,原生的 LLaMA 在中文问答效果上,确实一般 😂。
单样例微调
## 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
./sft_single.sh ../llama/models/Llama-2-7b-hf test q_proj,v_proj outputs/sft_output_llama_20240321
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
微调依然是稳如老狗,结果正常,耗时也基本一致。
微调后,模型部署和推理
## 1 在 adapter_config.json 文件中,确认 base_model_name_or_path 路径正确
## 2 调用模型,实验结果
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition}$ -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/llama
python3 cli_generate.py --seed=0 --prompt=你好 --model_path=../LLaMA-Factory/outputs/sft_output_llama_20240321 --use_peft
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
与 Gemma 类似,微调后的模型得到了相似的输出,即微调流程完成打通 (〃’▽’〃)。
总 结
主要面临的困难:
- xFormers 暂时没有较好的 AMD 适配方案。
主要解决方案:
- 曲线救国,尝试 Baichuan2、ChatGLM3、Gemma、LLaMA2 等其他大模型的微调,打通单样本微调流程。
- 目前为止,ChatGLM3、Gemma 和 LLaMA2 已经完整打通,可以用来继续探索;仅有 Baichuan2 主要卡在 xFormers 的兼容性问题上。
下一步计划:
- 实验完成,开始实操。
- 在具体业务场景中,使用数据集进行微调,并验证效果。
- 时间优化: 分布式多卡训练…
-
效果对比
: 模型、模型参数规模、数据规模…
- 遗留的 Baichuan2 未能打通微调流程,待源码阶段去解决。