大模型,小探索 —— 在 16G 的 AMD 上搞微调有多作死?(出坑篇)
微信公众号内容地址: https://mp.weixin.qq.com/s/Z6FQgXX25Dc9B7DzsT1iRA
微调实操: 数据集、超参数、模型结构,和评测指标。
总的来说,本次实操的思路如下:
- 数据阶段: 选定业务场景,找寻数据集。
- 爬坡阶段: 选定模型、固定基本训练超参数,增加数据量,达到初步效果。
- 调参阶段: 选定模型评测指标,固定数据,A/B Test 调优超参数。
- 对比阶段: 选定模型评测指标,固定数据、超参数,对比不同模型。
数据阶段
来源: https://tianchi.aliyun.com/competition/entrance/531904/information

初步预览如下,一共 5000 条数据:
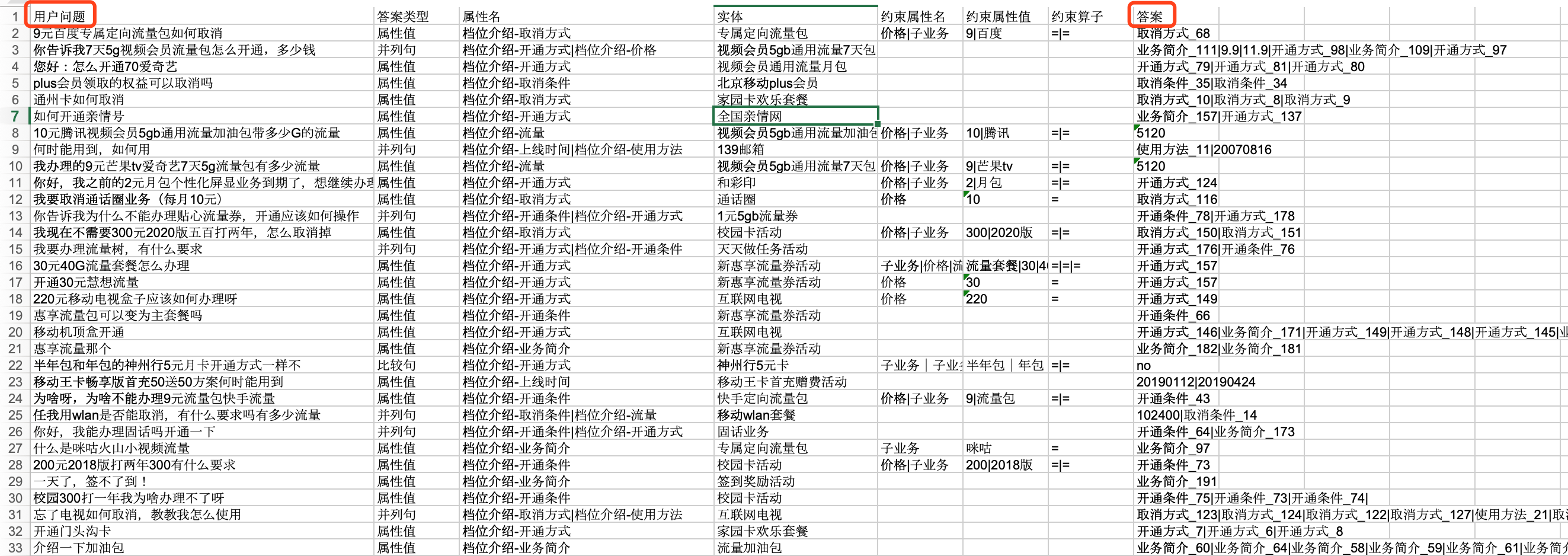
用户问题和答案列自然形成了 Q&A 的形式,无需进行过多转换处理;同时,官方网站的数据集,也减少了数据清洗、检验标注质量等操作的负担;更为重要的还是,便于验证:
- 其一,模型本身应该之前没有学习过类似知识。
- 其二,难度适中,相比于生成型任务,该任务更接近于分类。
- 其三,答案客观,较好验证结果。
可以将其转化成 telecom_train_5000.json,
[
{
"instruction": "回答中国电信手机用户的问题,9元百度专属定向流量包如何取消,应该怎么做?",
"input": "",
"output": "取消方式_68"
},
{
"instruction": "回答中国电信手机用户的问题,你告诉我7天5g视频会员流量包怎么开通,多少钱,应该怎么做?",
"input": "",
"output": "业务简介_111|9.9|11.9|开通方式_98|业务简介_109|开通方式_97"
},
...
]
将数据更新到 LLaMA Factory 框架中,
vi LLM/LLaMA-Factory/data/dataset_info.json
''' 文件内容
...
"telecom_train_5000": {
"file_name": "telecom_train_5000.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
},
'''
同样的操作,可以准备好 telecom_train_400、telecom_train_100、telecom_test_100 等数据集备用(截取数据时需要考虑数据平衡,即不同规模的数据集内,各类别的问题数量比例应尽量保持一致)。
爬坡阶段
首先,我们选定模型 gemma-2b (参数量相对较少,占用显存少,适合实验),并且先提问,看模型本身是否已经会了。
## 调用模型,实验结果
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition}$ -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
# Factory 训练,因此也得使用 Factory 推理(保持 template 一致)
CUDA_VISIBLE_DEVICES=0 python3 src/cli_demo.py --model_name_or_path ../gemma/models/gemma-2b --template default
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
初步看起来,模型本身并不知道怎么回答相关问题。

调整基本的 LoRA 参数
可以在 LLaMA-Factory/src/llmtuner/hparams/finetuning_args.py 文件中,通过 LoraArguments 查看更多的属性配置。

具体参数的含义后续会进一步展开,这里先靠直觉设置一些值。
vi LLM/LLaMA-Factory/sft_single.sh
''' 文件内容
...
--finetuning_type lora \
--lora_target $3 \
--lora_alpha 256 \
--lora_rank 128 \
--lora_dropout 0.1 \
--loraplus_lr_ratio 1.0 \
--loraplus_lr_embedding 1e-6 \
--use_rslora \
--use_dora \
--create_new_adapter \
--per_device_train_batch_size 8 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--learning_rate 5e-5 \
--num_train_epochs 5.0 \
...
'''
微调,400 样本
先使用少量 400 条数据进行尝试,看是否有效。
## 登远程节点,开始运行
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
# 微调
./sft_single.sh ../gemma/models/gemma-2b telecom_train_400 q_proj,v_proj,k_proj outputs/sft_output_gemma_20240328
...
# 查看文件大小
du -sh outputs/*
# 推理
CUDA_VISIBLE_DEVICES=0 python3 src/cli_demo.py --model_name_or_path ../gemma/models/gemma-2b --adapter_name_or_path outputs/sft_output_gemma_20240328 --template default --finetuning_type lora
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
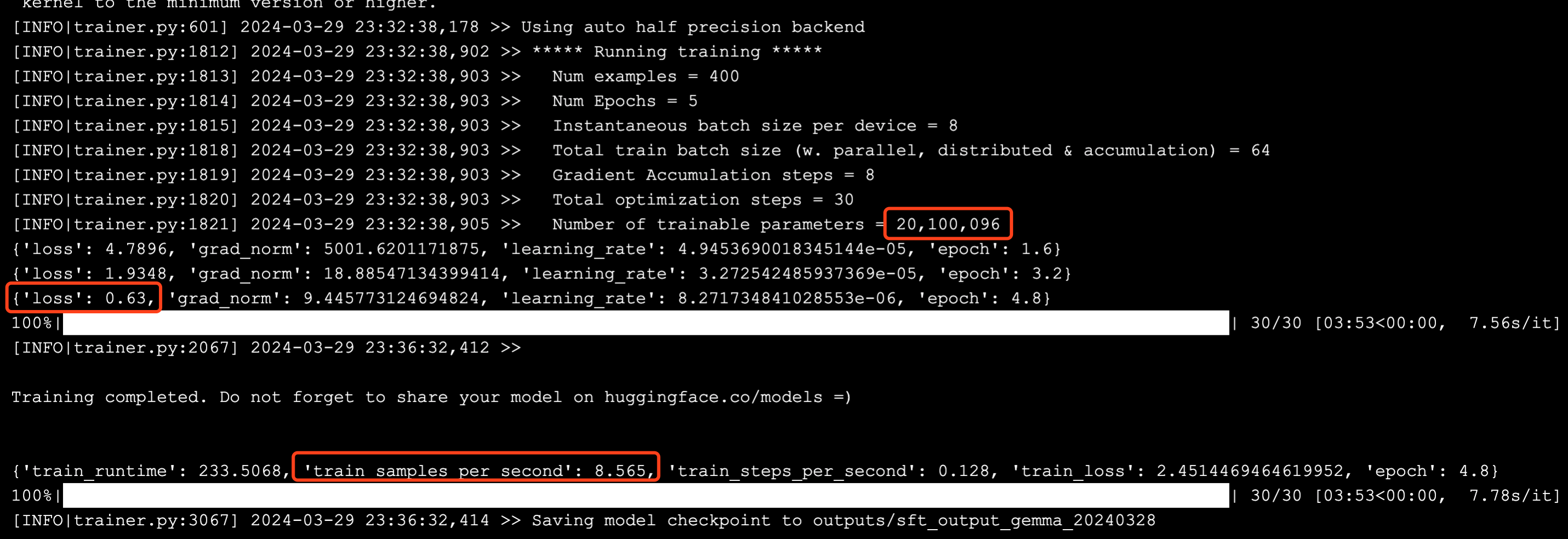
微调过程如下,主要可以看出以下数据:
- 模型训练的参数约为 2000w,约为总参数量的 1%。
- 从 loss 值来看,最后一次约为 0.6,直觉上来看,仍然较大,有提升空间。
- 每秒训练的样本数约为 8 个,所以总训练时长约为 400 * 5 epoch / 8 = 250 秒,即 4 分钟。可以推断,在不考虑分布式的情况下,完整训练 5000 个样本约需要 50 分钟。
对微调后的模型进行提问,结果如下。看起来,模型已经有所"进步"。

微调,5000 样本
其余操作均不变,使用 telecom_train_5000 进行微调,总共约耗时 40 分钟完成。
查看 loss 值曲线,最低达到 0.3 左右,较之前有更多提升。
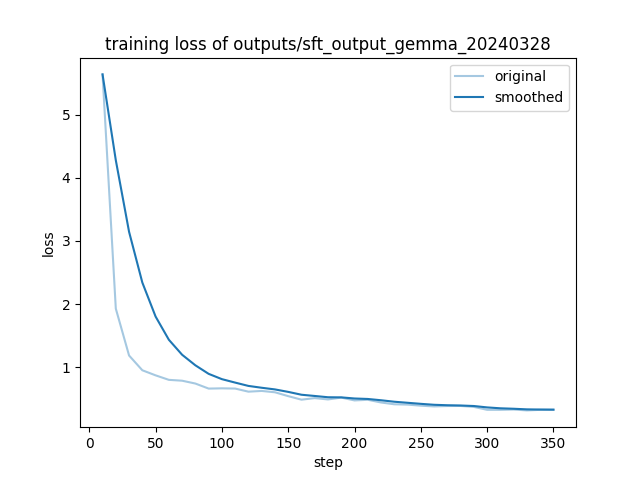
进行提问,效果进一步提升,虽然具体的数字没有答对 😂,但总的来说,爬坡已完成。

调参阶段
接下来,便是调参了。
首先,需要量化评测指标,一方面是用更多的客观评价维度来代替人的主观判断;另一方面也有利于自动化,提高调参效率。
量化评测指标
## 1 安装环境
source load_torch2.1_py3.sh
pip3 install nltk jieba rouge-chinese jsonlines
## 2 预测脚本,同时计算 BLEU 和 ROUGE
vi LLM/LLaMA-Factory/predict_single.sh
''' 文件内容
CUDA_VISIBLE_DEVICES=0 python3 src/train_bash.py \
--stage sft \
--do_predict \
--model_name_or_path $1 \
--adapter_name_or_path $2 \
--dataset $3 \
--template default \
--finetuning_type lora \
--output_dir $4 \
--overwrite_output_dir \
--per_device_eval_batch_size 1 \
--max_samples 150 \
--predict_with_generate \
--fp16
'''
chmod 764 LLM/LLaMA-Factory/predict_single.sh
## 3 评测脚本,精准率和召回率
vi LLM/LLaMA-Factory/predict_acc_rate.py
''' 文件内容
# -*- coding: utf-8 -*-
import jsonlines
import pandas as pd
import sys
# 获取命令行参数
if len(sys.argv) != 2:
print("Usage: python python.py path_to_jsonl_file")
sys.exit(1)
jsonl_path = sys.argv[1]
# 读取 JSONL 文件并转换为 DataFrame
data = []
with jsonlines.open(jsonl_path, 'r') as reader:
for line in reader:
data.append(line)
df = pd.DataFrame(data)
# 1. 新增一列“check”
df['check'] = (df['label'] == df['predict']).astype(int)
# 统计check等于1的占比
check_percentage = (df['check'] == 1).mean()
print("check等于1的占比:", check_percentage)
# 2. 新增一列“long answer”
df['long_answer'] = (df['label'].apply(len) > 10).astype(int)
# 统计在label等于1的样本中check等于1的占比
check_percentage_in_long_answer = df[df['long_answer'] == 1]['check'].mean()
print("在label等于1的样本中check等于1的占比:", check_percentage_in_long_answer)
'''
## 4 登远程节点,进行测试
# 申请资源,一般核卡比为 8:1
whichpartition
...
# salloc -p kshdtest -N 1 -n 8 --gres=dcu:1
salloc -p ${partition} -N 1 -n 8 --gres=dcu:1
# 查看作业列表,找到节点名
squeue
...
# 登录到节点上
ssh ${node_name}
# 主指令
source load_torch2.1_py3.sh
cd LLM/LLaMA-Factory
# 训练集上预测
./predict_single.sh ../gemma/models/gemma-2b outputs/sft_output_gemma_20240328 telecom_train_100 outputs/sft_predict_train_output_gemma_20240328
...
# 训练集的评测
python3 predict_acc_rate.py outputs/sft_predict_train_output_gemma_20240328/generated_predictions.jsonl
...
# 测试集上预测
./predict_single.sh ../gemma/models/gemma-2b outputs/sft_output_gemma_20240328 telecom_test_100 outputs/sft_predict_test_output_gemma_20240328
...
# 测试集的评测
python3 predict_acc_rate.py outputs/sft_predict_test_output_gemma_20240328/generated_predictions.jsonl
...
exit # 第一个 exit,登出节点
exit # 第二个 exit,退出作业
对 BLEU 和 ROUGE 的计算,有如下示例。简单来说,BLEU 类似于精确率,以模型结果中的总数量为分母,希望模型答的尽可能的对;ROUGE 类似于召回率,以参考结果中的总数量为分母,希望模型答的尽可能的全。

相关指标以及数据结果如下表所示:
| 指标 | 指标含义 | 值-训练集/% | 值-测试集/% |
|---|---|---|---|
| BLEU-4 | 对每个样本,将模型结果和标签按 4-gram 拆分后,计算精确率(模型结果为分母,命中值为分子);所有样本取平均。 | 49.43 | 53.58 |
| ROUGE-1 | 对每个样本,将模型结果和标签按 1-gram 拆分后,计算召回率(标签为分母,命中值为分子);所有样本取平均。 | 63.56 | 62.76 |
| ROUGE-2 | 对每个样本,将模型结果和标签按 2-gram 拆分后,计算召回率(标签为分母,命中值为分子);所有样本取平均。 | 46.37 | 51.98 |
| ROUGE-L | 类似的,考虑最长公共子序列,后进行计算。 | 59.19 | 59.73 |
| 准确率 Acc | 对所有样本,不以 n-gram 进行拆分,考虑完全一致,计算准确率。 | 19 | 24 |
| 召回率 Recall | 对所有样本,不以 n-gram 进行拆分,考虑完全一致,计算召回率。 | 13.79 | 21.74 |
在本次任务中,选择考虑完全一致的 Acc 和考虑覆盖性的 ROUGE-1 作为评判标准,进行调参。
LoRA 参数理解
LoRA(Low-Rank Adaptation of Large Language Models),微软研发的低秩自适应技术,旨在用两个低秩矩阵替代待更新的权重矩阵的增量。相当于在冻结原模型参数的情况下,只训练新增的网络层参数,进而大大减小微调的成本。
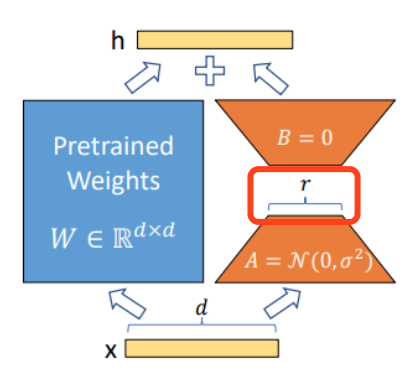
相关的参数包括:
- additional_target: 除了 LoRA 层之外(即除了两个低秩矩阵),要设置为可训练并保存在最终检查点中的模块名称。
- lora_alpha: 矩阵的标定因子,值越大,更新权重越积极;一般建议为 lora_rank 的 2 倍。
- lora_rank: 矩阵的秩,一般为 32、128、256。
- lora_dropout: dropout 率,以防止过拟合,增强泛化能力。
- loraplus_lr_ratio: 学习率比率(lr_B / lr_A)。
- loraplus_lr_embedding: LoRA 嵌入层的学习率。
- use_rslora: 是否使用秩稳定的 LoRA,即 rsLoRA(缩放因子 $\gamma = \frac{\alpha}{\sqrt{r}}$)。
- use_dora: 是否使用权重分解的 LoRA 方法(DoRA)。
- create_new_adapter: 是否创建一个具有随机初始化权重的新适配器。
- lora_traget: 用于指定应用 LoRA 的目标模块的名称。
- 使用 “all” 表示应用于所有线性模块。
- LLaMA: [“q_proj”, “k_proj”, “v_proj”, “o_proj”, “gate_proj”, “up_proj”, “down_proj”]
- ChatGLM: [“query_key_value”, “dense”, “dense_h_to_4h”, “dense_4h_to_h”]
- Baichuan: [“W_pack”, “o_proj”, “gate_proj”, “up_proj”, “down_proj”]
- …
实验报告
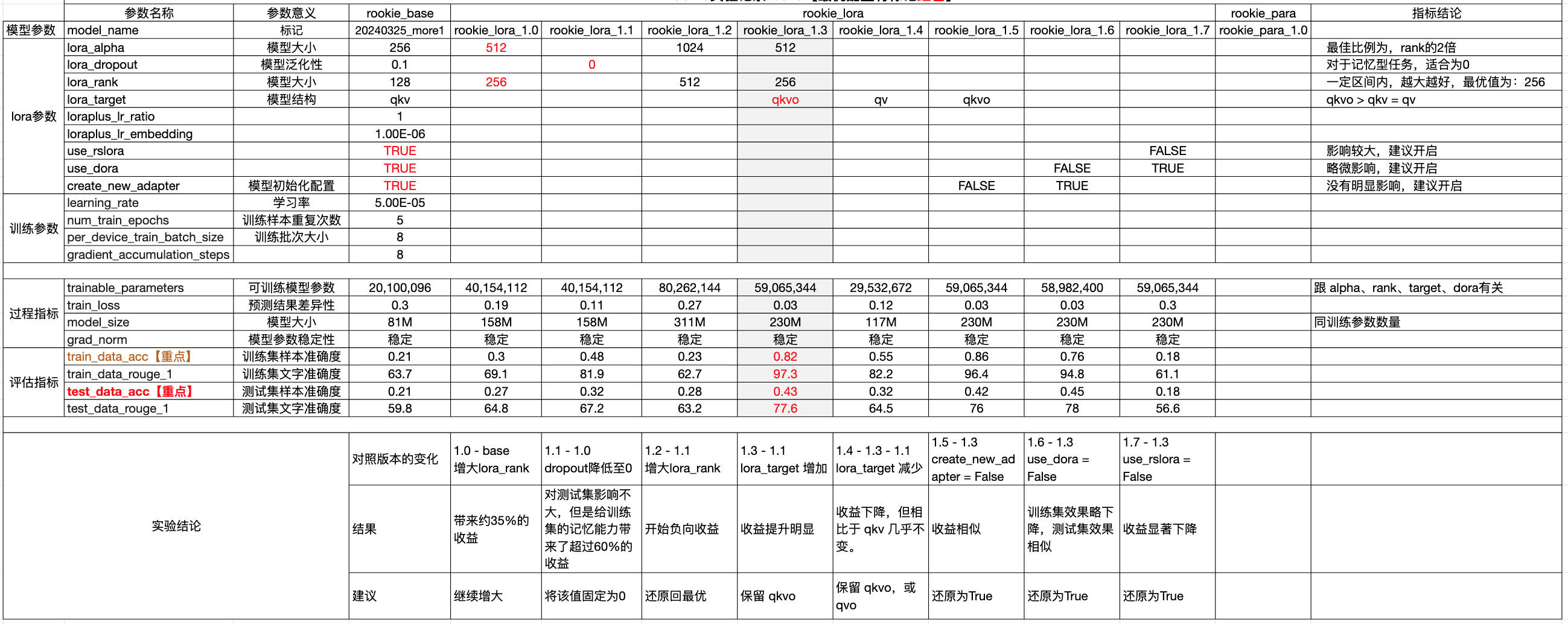
总的来说,经历了以上实验,在运营商知识数据集微调的场景下,有以下结论:
- lora_alpha、lora_rank、lora_target 和 use_rslora 这四个参数对模型结果影响明显
- lora_alpha 建议为 lora_rank 的 2 倍,lora_rank 的最优值目前为 256。
- lora_target,目前结论为 qkvo > qkv = qv。
- use_rslora,即秩稳定的 LoRA,开启后正向效果明显。
- 模型训练参数、训练后 adapter 的大小,跟 lora_alpha、lora_rank、lora_target 和 use_dora 有关。
目前的最优配置为:
lora_alpha: 512
lora_rank: 256
lora_dropout: 0.0
lora_target: q_proj, k_proj, v_proj, o_proj
loraplus_lr_ratio: 1.0
loraplus_lr_embedding: 1e-6
use_rslora: True
use_dora: True
create_new_adapter: True
使用该配置训练出来的模型,再次回答之前的问题,目前已经完全回答正确 ✌🏻。

对比阶段
使用相同的配置,训练 ChatGLM3,可以得到以下对比表格:
| 模型 | gemma-2b | ChatGLM3-6b |
|---|---|---|
| 训练时长 | 45 分钟(batch_size=8) | 75 分钟(batch_size=2) |
| 可训练模型参数 | 59,065,344 | 62,519,296 |
| train_loss | 0.03 | 0.01 |
| 模型大小 | 230M | 240M |
| train_data_acc | 82% | 94% |
| train_data_rouge_1 | 97.3% | 99.2% |
| test_data_acc | 43% | 49% |
| test_data_rouge_1 | 77.6% | 79.4% |
可以看出,ChatGLM3 还是在各指标上都取得了领先的。同时,也可以运行并看一次具体的推理,它也正确回答了问题。

然而好景不长,当测试模型的通用能力的时候,会发现如下输出 😭!
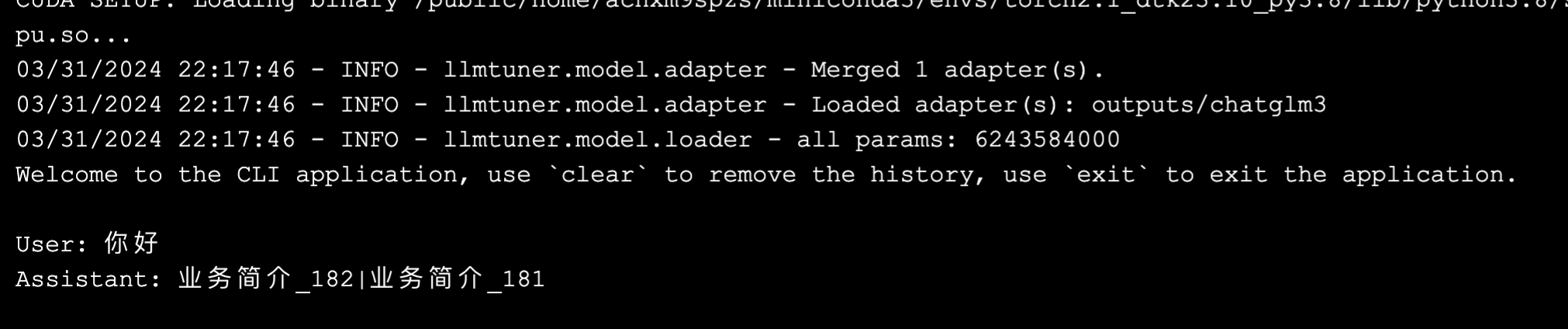
属于是遗忘式学习了,专业能力提升了,模型的通用能力却下降了。有待于进一步研究混合数据训练等方案,同时兼顾两者了。

至于另一个模型,LLaMA-7b,很不幸,爆显了 😂。有待于进一步研究分布式微调,来实现时间和空间上的优化了。
总 结
主要完成:
- 使用运营商知识数据集,对 gemma-2b 模型进行微调,并调参至更优。
- 使用相似的配置,对 ChatGLM3 进行微调,并进行对比。
待探索:
- 分布式多卡微调,解决 LLaMA-7b 的训练爆显的问题。
- 混合数据训练,解决微调过拟合——通用能力下降的问题。
- Baichuan2 的微调。